Einleitung
Wir importieren bereits seit März 2017 Daten des https://luftdaten.info Projekts ins System nach https://luftdaten.hiveeyes.org/, weitere Details darüber kann man unter luftdaten.info — Kotori 0.22.7 documentation nachlesen.
Dank gemeinsamem Troubleshooting bei Apparent data-loss for two luftdaten.info sensor nodes und folgenden Diskussionen rund um die Importtechnik konnten wir der luftdatenpumpe.py eine Runderneuerung spendieren. Danke an dieser Stelle an @roh, @wtf, @einsiedlerkrebs, @weef und @clemens!
Die Verbesserungen betreffen zwei Bereiche: Funktionalität und Leistungsfähigkeit.
Funktionalität: Filterung
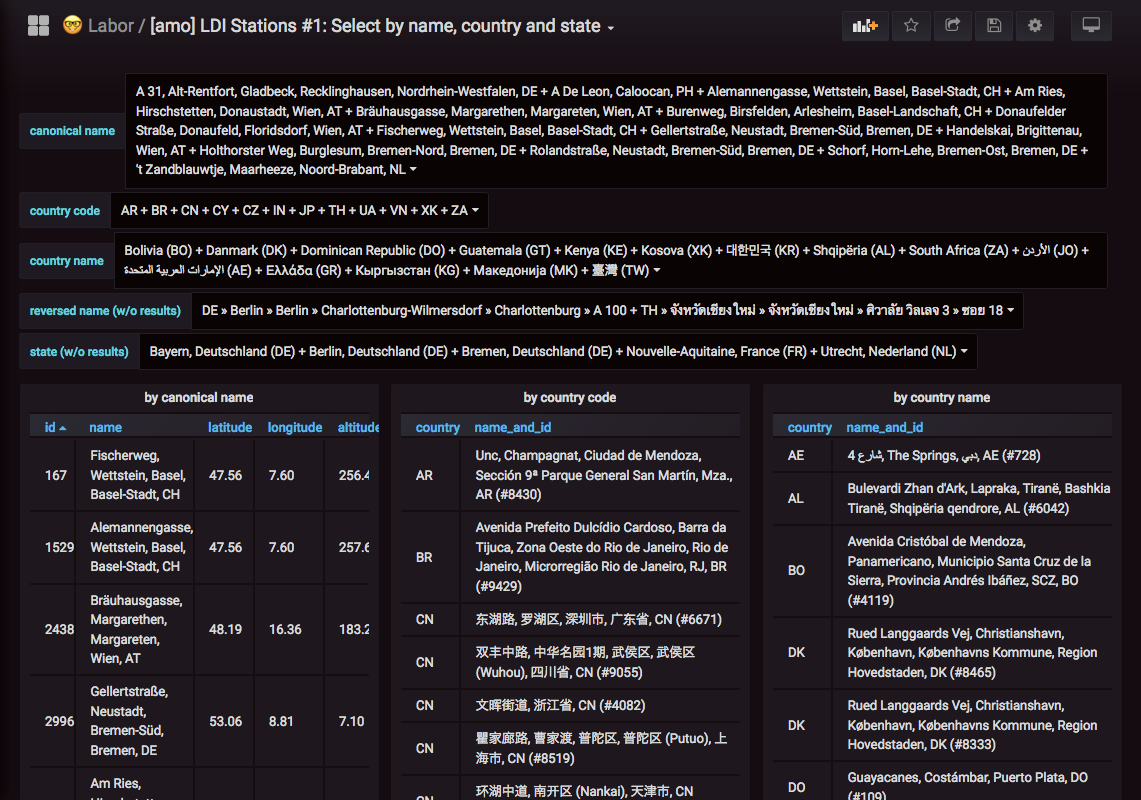
Das Programm "luftdatenpumpe" versteht nun die Optionen "--sensor=" sowie "--location=", denen derzeit jeweils eine oder mehrere kommaseparierte numerische IDs übergeben werden können, um die Ausgabe auf diese Stationen bzw. Sensoren zu beschränken.
Funktionalität: Stationsliste
Die bei der Filterung akzeptierten Werte für die genannten Optionen können über die Stationsliste herausgefunden werden, in der einfachsten Form ist man davon nur durch einen Aufruf von
luftdatenpumpe stations
entfernt.
Zusammen mit reverse geocoding dauert es zwar länger, man erlangt dadurch jedoch auch einen besseren Überblick. Durch die neuen Filtermöglichkeiten kann der Vorgang nun individuell eingeschränkt werden, um angenehmere Laufzeiten zu erzielen, beispielsweise per:
luftdatenpumpe stations --reverse-geocode --station=28,1071
Leistung
Die Luftdatenpumpe kann von nun an statische JSON Dateien à la luftdaten-stations-grafana.json für die Environmental Metadata Library erzeugen, die im Zuge von Map Grafana template variable identifiers to text labels using HTTP requests zum Einsatz kommen und im neuen Feinstaub Verlauf Berlin Dashboard bereits verwendet werden.
In Folge dessen können die Meßdaten selbst nun ohne textuelle Metadaten in der InfluxDB Datenbank auskommen, so dass wir beim regulären Aufruf zum Datenimport nun auf die teure --reverse-geocode Option verzichten können. Der Importvorgang wird zukünftig also deutlich flotter über die Bühne gehen:
luftdatenpumpe readings --target=mqtt://localhost/testdrive/info/earth/77/data.json
Total: 6s
Die Erzeugung der statischen Stationsliste dauert dementsprechend weiterhin lange, kann zukünftig jedoch viel seltener laufen, etwa einmal pro Tag:
luftdatenpumpe stations --reverse-geocode --target=json.grafana+stream://sys.stdout
Total: 22m
Rückblick
Bisher benötigte der Import gute 20(!) Minuten, obwohl(!) die Antworten des reverse geocodings über die Nominatim API lokal gecached werden.
Die Liste der Stationsnamen wurde über folgende Anfrage an die Datenbank aus den Meßdaten selbst berechnet:
SHOW TAG VALUES FROM earth_43_sensors WITH key="location_name"