Problem
Irgendwoher kam eine Meldung, dass Graphen, die auf How to Visualize 2-Dimensional Temperature Data in Grafana eingebettet sind, nicht schnell genug rendern.
Irgendwoher kam eine Meldung, dass Graphen, die auf How to Visualize 2-Dimensional Temperature Data in Grafana eingebettet sind, nicht schnell genug rendern.
Ich konnte dabei z.B.
https://weather.hiveeyes.org/grafana/render/d-solo/L0hYHh5mk/wtfs-playground?orgId=1&from=now-2h&to=now&refresh=15m&panelId=5&width=320&height=300&tz=UTC%2B02%3A00
identifizieren.
Wenn man dem nachgeht, landet man beim Dashboard
https://weather.hiveeyes.org/grafana/d/L0hYHh5mk/wtf-playground-legacy?orgId=1&from=now-2h&to=now&refresh=15m&width=320&height=300&tz=UTC%2B02:00
Und wenn man dort unter die Haube schaut, sieht man, dass zwei Requests zur Datenbank hundert Jahre für eine Antwort brauchen:
Es handelt sich dabei um folgende Abfragen:
SHOW TAG VALUES WITH KEY = "code" WHERE "type" = 'background' AND "end" !~ /./
SHOW TAG VALUES WITH KEY = "code" WHERE "type" = 'background' AND "end" !~ /./ AND "code" =~ /DEBB.*/
Beide Abfragen gehen gegen die Datenbank "uba_list".
Apfel. Birne. Die beiden später im Post genannten Requests haben nix mit dem SVG-Panel zu tun. Das Dashboard trägt nicht umsonst “Playground” UND “legacy” im Titel! ;)
Verstehe. Danke. Sie werden aber scheinbar trotzdem aus dem gleichen Dashboard heraus abgesetzt? Falls das so ist, könnten wir die SVG Maps aus dem Dashboard herauslösen?
Hier auf der commandline nachgestellt:
root@eltiempo:~# time influx -database uba_list -execute 'SHOW TAG VALUES WITH KEY = "code" WHERE "type" = "background" AND "end" !~ /./'
real 0m42.407s
Ja, das wird vmtl. in den Dashboards-Variablen ausgelöst. Klar, willst Du, soll icke?
Die SHOW TAG VALUES Abfrage sollte mit FROM station auf die gewollte Tabelle eingeschränkt werden, der Basisteil (beware of the Gänsefüßchen) der Abfrage sollte also folgendermaßen lauten:
SHOW TAG VALUES FROM station WITH KEY = "code" WHERE type = 'background'
Damit klappt die Verarbeitung auch deutlich flotter:
$ time influx -database uba_list -execute "SHOW TAG VALUES FROM station WITH KEY = code WHERE type = 'background'"
| real | 0m0.256s |
|---|---|
| user | 0m0.232s |
| sys | 0m0.028s |
Gut, das ist jetzt zwar noch ohne den regex-match constraint, der da noch angehängt werden muss und der höchstwahrscheinlich ohne Wenn und Aber einen Full table scan - Wikipedia nach sich ziehen wird:
Full table scans [2] are usually the slowest method of scanning a table due to the heavy amount of I/O reads required from the disk which consists of multiple seeks as well as costly disk to memory transfers.
… selbst dieser sollte in jenem speziellen Fall hoffentlich nicht allzusehr ins Gewicht fallen, da die Kardinalität der in Frage kommenden Tabelle nicht sehr hoch ist:
$ influx -database uba_list -execute "SELECT COUNT(*) FROM station"
time count
---- ---------------
0 2072
Das klappt eben allerdings nur, wenn man den Tabellennamen in der Abfrage auch angibt. Sonst macht InfluxDB die “SHOW TAG VALUES …” Abfrage über alle Tabellen der Datenbank - und die andere Tabelle für die Meßdaten hat deutlich mehr Einträge:
$ influx -database uba_list -execute "SELECT COUNT(*) FROM parameter"
time count
---- --------------
0 18611
Dadurch fallen dann etwaige andere nicht ganz optimale Dinge noch mehr ins Gewicht.
Zusammen mit dem constraint "end" !~ /./wird das dann zwar im Vergleich immer noch deutlich besser, ist aber eigentlich immer noch viel zu lahm unterwegs:
$ time influx -database uba_list -execute 'SHOW TAG VALUES FROM station WITH KEY = "code" WHERE "type" = "background" AND "end" !~ /./'
real 0m12.947s
Full table scan - Wikipedia (!!1elf!!) olé…
Die machen grade richtig Dampf, diese Abfragen (während ich gerade überall in die Dashboardvariablen FROM station reineditiere, wie von Euch vorgeschlagen):
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
420 influxdb 20 0 55.861g 0.024t 0.010t S 400.3 57.6 457:04.26 influxd
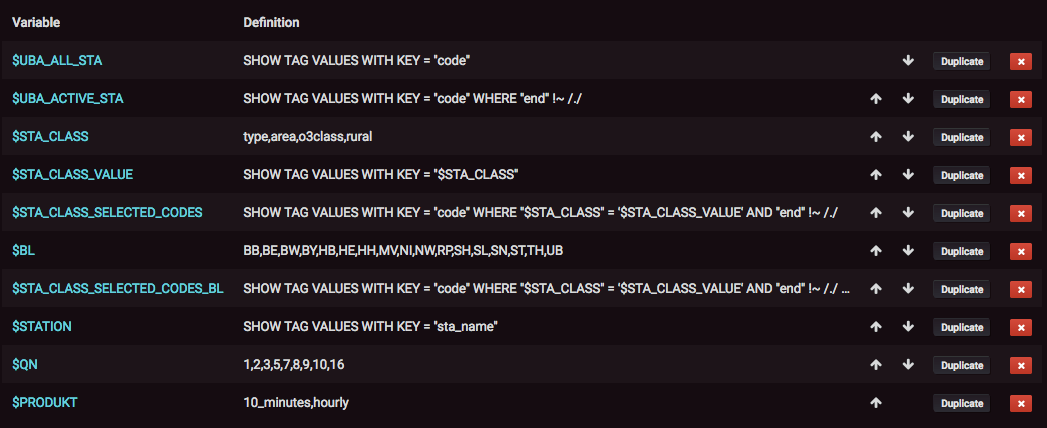
Wir haben nun überall in die Grafana variable query expressions das hier noch fehlende FROM station hineineditiert:
Damit konnten wir im Vergleich zu vorhin
immerhin Faktor 6x an Leistung rausholen:
Jetzt kann man sich fast trauen, das hier direkt zu verlinken:
$ time http 'https://weather.hiveeyes.org/grafana/render/d-solo/L0hYHh5mk/wtfs-playground?orgId=1&from=now-2h&to=now&refresh=15m&panelId=5&width=320&height=300&tz=UTC%2B02%3A00'
real 0m11.977s
Allerdings könnte es noch besser werden.
Wir müssen langfristig mal richtig an die Datenhaltung ran, weil wir solche Dinge ja grundsätzlich schon in Echtzeit rendern können wollen, stimmts? Zusammen mit @wtf haben wir das noch für diesen Winter eingeplant, zu Versprechungen können wir uns aber nicht hinreißen lassen ;].
Konkret hoffe ich, dass wir einige Dinge aus der Erneuerung der Luftdatenpumpe auch für (in diesem Fall) UBA anwenden können und damit die Stationslistendatenhaltung und alles was dazugehört auf eine über alle Datenquellen/Meßnetzwerke hinweg gemeinsame Grundlage stellen können.
Noch konkreter handelt es sich dabei vor allem um Filterungsaktionen direkt auf den Daten, bei denen geospatiale Kriterien hinsichtlich Stationsfilterungen eine Rolle spielen. Damit wir die insgesamte Datenmenge reduzieren können, die von InfluxDB für einen schnellen Indexzugriff benötigt wird, wollen wir die InfluxDB Datenbank von allen unnötigen Metadaten befreien und stattdessen in einer PostgreSQL Datenbank ablegen.
Am Beispiel von LDI sah das bislang vielversprechend aus
wir müssen jedoch gemeinsam noch letzte Details ausloten bzw. die ganze Angelegenheit dem Praxistest unterziehen, bevor wir die Vorgehensweise auch auf die anderen Datenquellen ausweiten können.
Insgesamt versprechen wir uns dadurch einen deutlichen Leistungsschub bei der Datenwurschtelei und gewinnen so die Möglichkeit, weitere Datenquellen zu erschließen und anspruchsvollere Berechnungen bzw. Visualisierungen zu ermöglichen.
Weitere Optimierung: Wir sollten "end" = '' statt "end" !~ /./ verwenden, das ist deutlich flotter unterwegs. Als proof-of-concept versuchen wir ein paar Abfragen.
> SELECT COUNT(*) FROM station WHERE type = 'background'
name: station
time count_localcode
---- ---------------
0 1229
> SELECT COUNT(*) FROM station WHERE type = 'background' AND "end" = ''
name: station
time count_localcode
---- ---------------
0 599
> SELECT COUNT(*) FROM station WHERE type = 'background' AND "end" !~ /./
name: station
time count_localcode
---- ---------------
0 599
Na also:
$ time http 'https://weather.hiveeyes.org/grafana/render/d-solo/L0hYHh5mk/wtfs-playground?orgId=1&from=now-2h&to=now&refresh=15m&panelId=5&width=320&height=300&tz=UTC%2B02%3A00'
real 0m3.950s
Vielen Dank an @clemens für die Meldung!