ja, war ja nur ein bisschen die linkspfelitaste gedrückt halten und dann ein “s” ;-)
vielsten dank und gute nacht!
habe die Beispielzeile nochmal überarbeitet. Das war alles nur theoretisch zusammgefasst, daher danke @mois fürs praktische testen!
Welche Schnittstelle nutzen wir in der Zukunft?
Wir haben ja jetzt die beiden Möglichkeiten annotations über den
- Kotori via HTTP als auch via MQTT oder
- nativ über Grafana via HTTP
erzeugen.
Wenn ich es richtig gesehen habe erscheinen die annotations via Kotori auf allen Panels eines Dashboards während zumindest die interaktiv erzeugten nur im Panel angezeigt werden von dem sie aus erzeugt wurden.
Welche Methode sollen wir zukünftig nutzen? Landen beide Wege in der gleichen Datenbank?
Wie würde der native HTTP-Aufruf über die Kommandozeile mt einem json-Objekt ausschauen, s.: Annotations HTTP API | Grafana Documentation
Hintergrund: Ich würde gerne die Phänologie-Daten eines Standorts exemplarisch in ein Grafana-Panel schreiben.
1 Like
Ich habe es jetzt mal mit der “alten” API über so was versucht
http POST https://swarm.hiveeyes.org/api/hiveeyes/phenodata/berlin/dahlem/event title='Schneeglöckchen' text='Blüte Beginn' tags='phenodata,berlin,dahlem,schneeglöckchen,blüte beginn' time='2018-02-17T00:00:00 CET'
http POST https://swarm.hiveeyes.org/api/hiveeyes/phenodata/berlin/dahlem/event title='Hasel' text='Blüte Beginn' tags='phenodata,berlin,dahlem,hasel,blüte beginn' time='2018-02-19T00:00:00 CET'
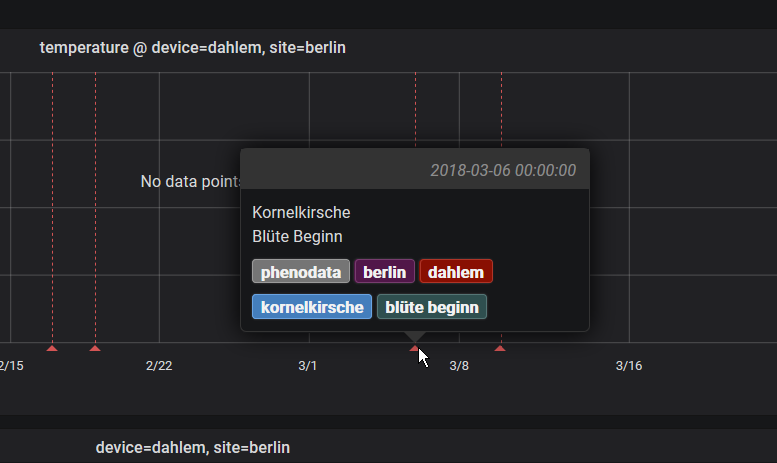
http POST https://swarm.hiveeyes.org/api/hiveeyes/phenodata/berlin/dahlem/event title='Kornelkirsche' text='Blüte Beginn' tags='phenodata,berlin,dahlem,kornelkirsche,blüte beginn' time='2018-03-06T00:00:00 CET'
http POST https://swarm.hiveeyes.org/api/hiveeyes/phenodata/berlin/dahlem/event title='Huflattich' text='Blüte Beginn' tags='phenodata,berlin,dahlem,huflattich,blüte beginn' time='2018-03-10T00:00:00 CET'
http POST https://swarm.hiveeyes.org/api/hiveeyes/phenodata/berlin/dahlem/event title='Forsythie' text='Blüte Beginn' tags='phenodata,berlin,dahlem,forsythie,blüte beginn' time='2018-03-27T00:00:00 CET'
http POST https://swarm.hiveeyes.org/api/hiveeyes/phenodata/berlin/dahlem/event title='Winterraps' text='Längenwachstum Beginn' tags='phenodata,berlin,dahlem,winterraps,längenwachstum beginn' time='2018-03-28T00:00:00 CET'
http POST https://swarm.hiveeyes.org/api/hiveeyes/phenodata/berlin/dahlem/event title='Schlehe' text='Blüte Beginn' tags='phenodata,berlin,dahlem,schlehe,blüte beginn' time='2018-03-29T00:00:00 CET'
http POST https://swarm.hiveeyes.org/api/hiveeyes/phenodata/berlin/dahlem/event title='Rosskastanie' text='Austrieb Beginn' tags='phenodata,berlin,dahlem,rosskastanie,austrieb beginn' time='2018-03-29T00:00:00 CET'
http POST https://swarm.hiveeyes.org/api/hiveeyes/phenodata/berlin/dahlem/event title='Sal-Weide' text='Blüte Beginn' tags='phenodata,berlin,dahlem,sal-weide,blüte beginn' time='2018-03-30T00:00:00 CET'
http POST https://swarm.hiveeyes.org/api/hiveeyes/phenodata/berlin/dahlem/event title='Stachelbeere' text='Austrieb Beginn' tags='phenodata,berlin,dahlem,stachelbeere,austrieb beginn' time='2018-03-30T00:00:00 CET'
http POST https://swarm.hiveeyes.org/api/hiveeyes/phenodata/berlin/dahlem/event title='Hänge-Birke' text='Austrieb Beginn' tags='phenodata,berlin,dahlem,hänge-birke,austrieb beginn' time='2018-03-31T00:00:00 CET'
http POST https://swarm.hiveeyes.org/api/hiveeyes/phenodata/berlin/dahlem/event title='Apfel, frühe Reife' text='Austrieb Beginn' tags='phenodata,berlin,dahlem,apfel, frühe reife,austrieb beginn' time='2018-04-01T00:00:00 CET'
http POST https://swarm.hiveeyes.org/api/hiveeyes/phenodata/berlin/dahlem/event title='Spitz-Ahorn' text='Blüte Beginn' tags='phenodata,berlin,dahlem,spitz-ahorn,blüte beginn' time='2018-04-02T00:00:00 CET'
Die Aufrufe habe ich mir mit den über phenodata erzeugten Listen und einer Excel-Datei gebastelt, kann man sicher auch nett mit Python scripten: :-)
add-annotations-berlin-dahlem-2018.xlsx (16.1 KB)
Edit: Hier muss man noch etwas nachbessern, der tag “Apfel, frühe Reife” wird wegen des Kommas in zwei tags geteilt, d.h. entweder “,” ersetzen oder maskieren. (to be done ;-)
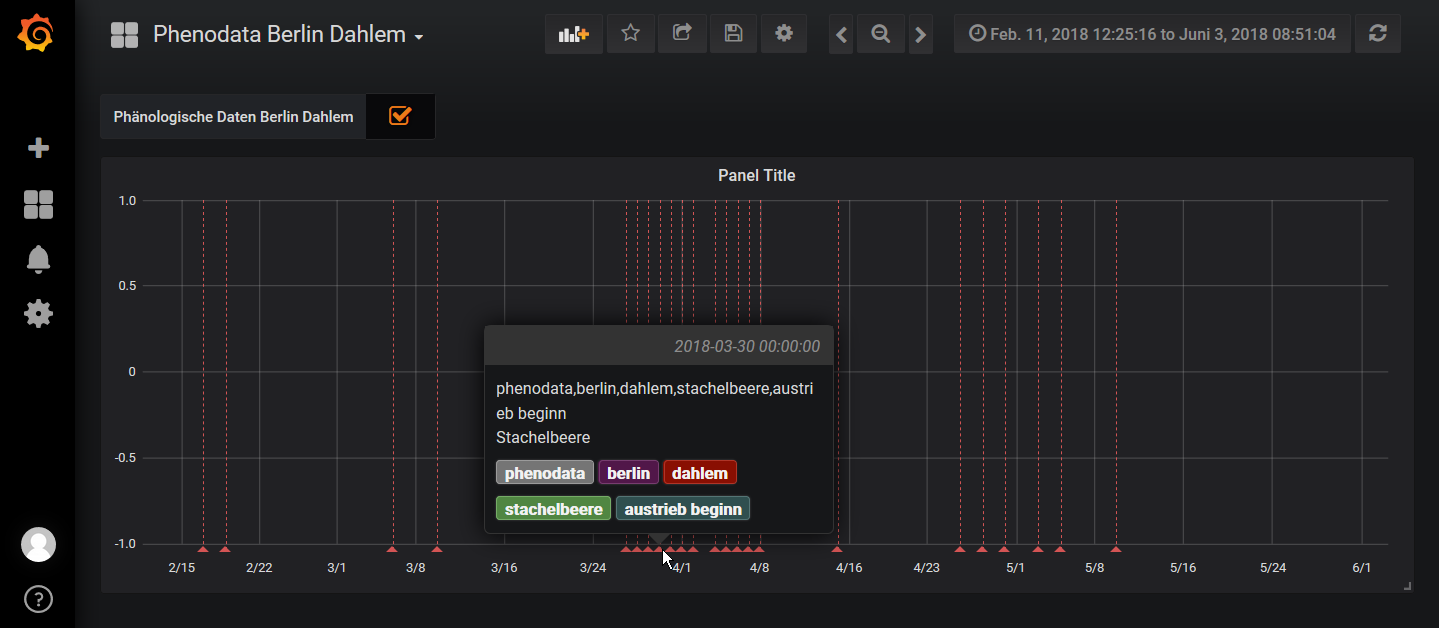
Hier eine kleiner Einblick, es fehlen noch ein paar Events, da ich die Aufrufe zusammen in die Komandozeile kopiert haben und sich mein Rechner oder der Server etwas verschluckt hat.
https://swarm.hiveeyes.org/grafana/d/yjkf6okik/phenodata-berlin-dahlem
1 Like
Das ist leider nicht so, default ist keine annotation aktiviert:
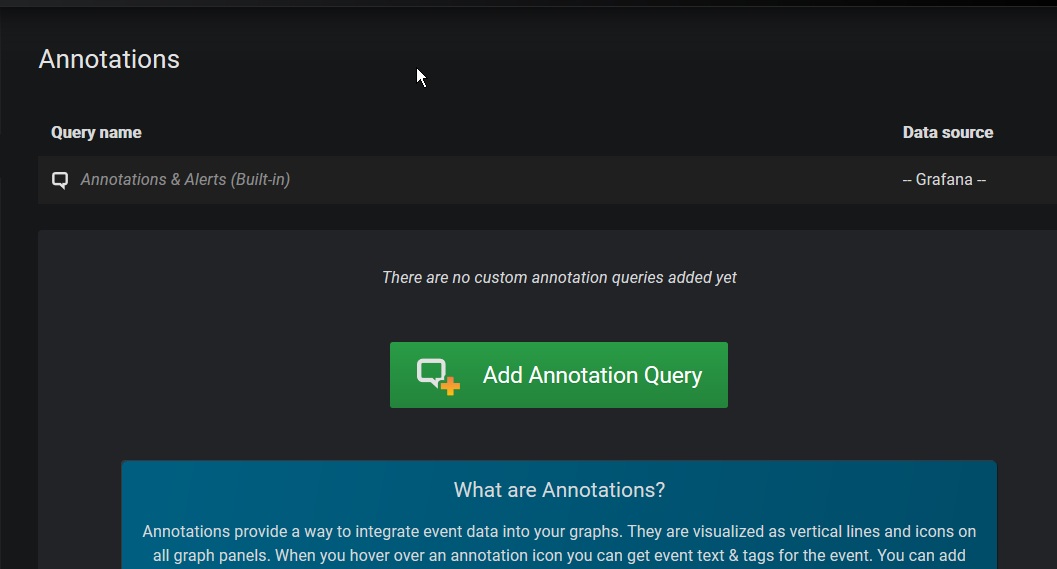
Die dann tatsächlich einzurichten ist gar nicht so einfach, weil man erst mal rausfinden muss wie die Datenbank / “Tabelle” / Untergruppe genau benannt ist.
Weiter passen die Feldnamen nicht, im Demo-annotation dashboard gibt es drei Felder
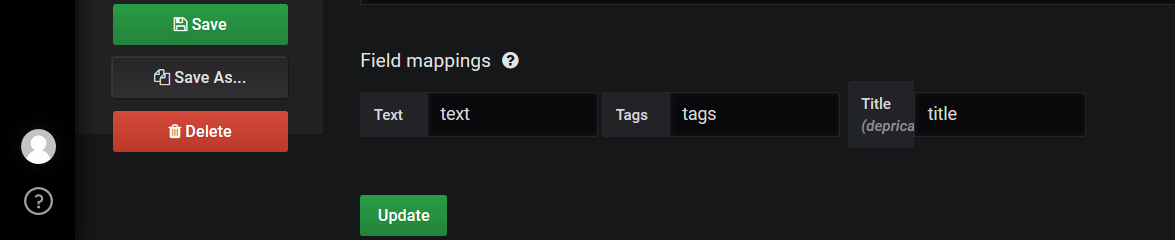
während bei meiner neu erzeugten Datenbank nur zwei Felder erscheinen
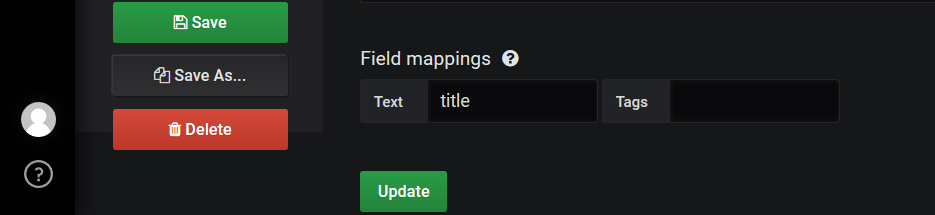
Und die werden auch nicht korrekt zugeordnet
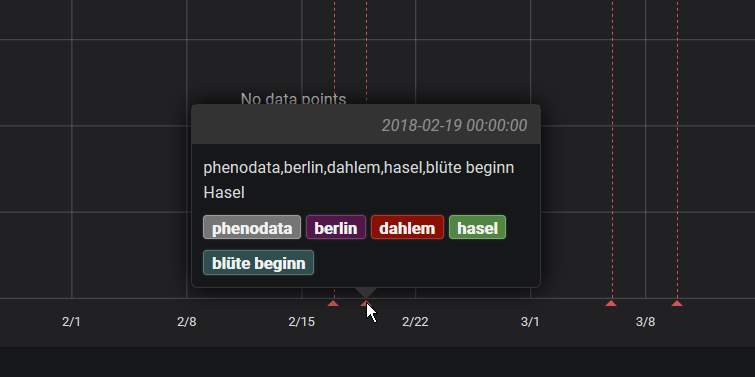
die Tags erscheinen da wo eigentlich der Titel hin soll …
Wenn es annotations gibt, die genau den gleichen timestamp haben
2018-03-29 Schlehe
2018-03-29 Rosskastanie
ich habe beide mit time=‘2018-03-29T00:00:00 CET’ eingetragen - erscheint immer nur die zuletzt eingetragene. :-(
Klar, alle, die automatisch ‘on-boarded’ haben (z.B. alle “hiveeyes open-hive-* automatic”) haben (mindestens) einen Kanal namens Events default_1. Beim manuellen Anlegen eines dashboards, so wie Du das jetzt bestimmt gemacht hast, passiert das nicht.
1 Like
Ah, die automatic haben das. Gut, dann habe ich das “beim Anlegen des Dashboards” falsch verstanden. Und siehe, da brauche ich auch nicht die Annotation-DB auswählen und tags / title / text stimmen auch. Da habe ich mich unnötig gequält:
Hi Clemens,
schön, dass Du Dich für die Details der Implementierung bei den Annotationen interessierst.
Jep, habe ich auch so beobachtet.
Da bin ich mir auch noch nicht sicher, was zukünftig besser passt bzw. für die Benutzer komfortabler ist. Wir wollen ja - wie immer ;] - dass sich das System DWIM-konform verhält.
Nein, die Annotationen, die man derzeit über die Kotori API absetzen kann, landen in der InfluxDB, während die im Grafana selbst erzeugten Annotationen in der Grafana-internen Datenbank gespeichert werden.
Danke für den Link! Es wäre ja ggf. schön, wenn man über die Kotori API zukünftig beide Varianten ansteuern kann, nicht?
Toll, Du hast ja mittlerweile schon erste Erfolgserlebnisse erzielt, stimmts? Gratuliere!
Viele Grüße,
Andreas.
Exzellent!
Feine Idee! Das können wir gern bei Gelegenheit für "phenodata" nachreichen.
Sehr schön!
ja, bei der neuen Art der interactive annotations ist offenbar noch nicht alles so beisammen, wie es könnte. Merkwürdigerweise gilt title als deprecated, wie auch aus einem Bild oben von Dir zu sehen ist. Es sieht so aus, als wenn aus irgendeinem Grund title zugunsten in etwas der interactive annotations aufgegeben worden sei - immerhin scheint die HTTP annotations API title noch wie immer zu honorieren, und ein gültiger title wird offenbar noch richtig angezeigt.
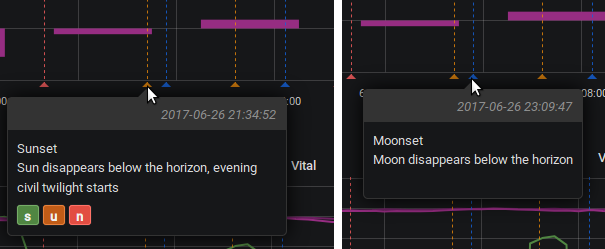
Aber jedenfalls ist das noch nicht ganz fertig, z.B. bei der sunmoon datasource im Grafana werden die tags innerhalb dessen sun* events’ auto annotations verhackstückt, und der Mond bekommt keine tags mehr:
1 Like
Wenn wir die phänologischen Daten irgendwann mit den Sensordaten in Zusammenhang bringen wollen (Blühbeginn Obst → Gewichtsanstieg Volk) wäre es vorteilhaft beides in der selben Datenbank zu haben, daher sollten wir uns für einen Speicherort entscheiden und für mein Verständnis wäre das die InfluxDB. Daher würde ich sagen, wenn der Kotori eines beherrscht braucht er nicht unbedingt das andere noch. - Ausser die Funktionalität ist unterscheidlich und wir wllen / brauchen das und können es nicht anders realisieren:
Ich denke da an die Anzeige in allen panels eines dashboards (über Kotori) vs. Anzeige nur in einem Panel (interaktive annotations). Z.B. Zarge aufgesetzt, daher +10 kg, das macht nur im Gewichts-Panel Sinn und verwirrt bie den Temperatur-Daten.
Wichtiger wäre mir aber, dass wir die imkerlichen Eingriffe auch von der Grafik aus “nachtragen” können und dass dann in der Beep-App landet, also der Eintrag entlang der Zeitachse, Daten dann aber in der Stockkarte.
2 Likes
Unter Annotationen im Grafana über die HTTP/MQTT API findest Du weitere Details dazu, daraus ist auch das Programm RPi-Beelogger/set-mqtt-annotation.py at master · beelogger/RPi-Beelogger · GitHub von @mhies entstanden.
Darüber hinaus wollen wir Dich noch auf Ereignisse interaktiv im Grafana annotieren hinweisen, hier wird die alternative Variante zum interaktiven Erstellen und Bearbeiten von Annotationen beschrieben.
Genau, das entspräche mit viel Phantasie der minimalen Variante einer Stockkarte. Wir wollen die Möglichkeiten zu reichhaltigeren Stockkarteneinträgen an dieser Stelle zukünftig noch ausbauen. Auch phänologische Informationen könnte man auf diese Weise einblenden, wie z.B. bei phenodata-berlin-dahlem schonmal geübt.
OK, das werde ich mir mal anschauen. Meine Frage war eher ob jemand dafür schon etwas fertiges hat, evtl. auch als App. Aber das kommt vielleicht irgendwann noch. Ich denke auch mal, daß dann nicht jeder alles öffentlich haben will (z.B. die Erträge).
Zu den Phenodaten könnte man ja überlegen die Datenbank zum Blühphasenmonitoring vom DLR ähnlich wie die DWD Wetterdaten anzubinden. Wobei da natürlich die Standorte nicht fest sind, man müsste also mit Radien oder Regionen arbeiten.
Ich hatte den code direkt aus dem Post (Daten per MQTT ans Backend auf swarm.hiveeyes.org übertragen) kopiert, nicht aus dem Beispiel hinter dem link…
Zu beachten ist aber, dass beide Arten von Annotationen in unterschiedliche Datenbanken abgespeichert werden. Erstere werden in der InfluxDB neben den Meßdaten abgelegt, zweitere werden standardmäßig nur in der Grafana-eigenen Datenbank gespeichert.
@einsiedlerkrebs und ich haben gerade herausgefunden, dass der Speicherort der interaktiven, per Grafana editierbaren Annotationen konfigurierbar ist und es damit vermutlich ebenfalls möglich ist, die Daten in der InfluxDB zu speichern.
Wir werden zusehen, dass wir das Subsystem in die entsprechende Richtung treiben, so dass sowohl die interaktiv als auch die per API erzeugbaren Annotationen im selben Speicherort landen.
und bei einem darstellungsproblem wäre ich auch noch für tipps dankbar. es ist ein bisschen wie das von clemens vor gut einem jahr: in dem einen dashboard siehts gut aus:
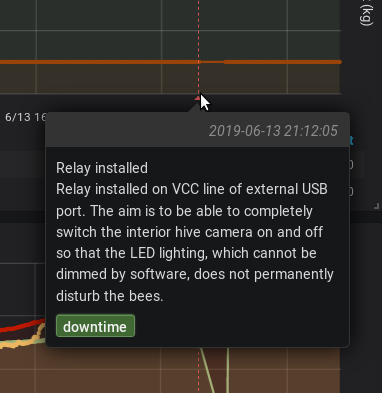
in dem anderen erscheint meine datenquelle statt dem titel:
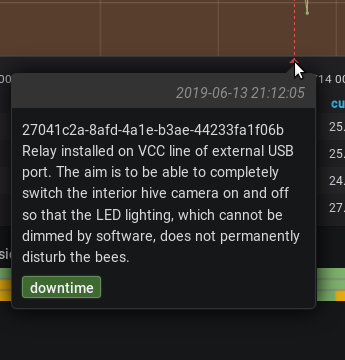
hat’s mit dem anlegen des dashboards zu tun (hab ich manuell gemacht, indem ich json kopiert und gepastet und dabei den hash in der url verändert habe)?
lässt sich das im nachhinein noch fixen?
1 Like