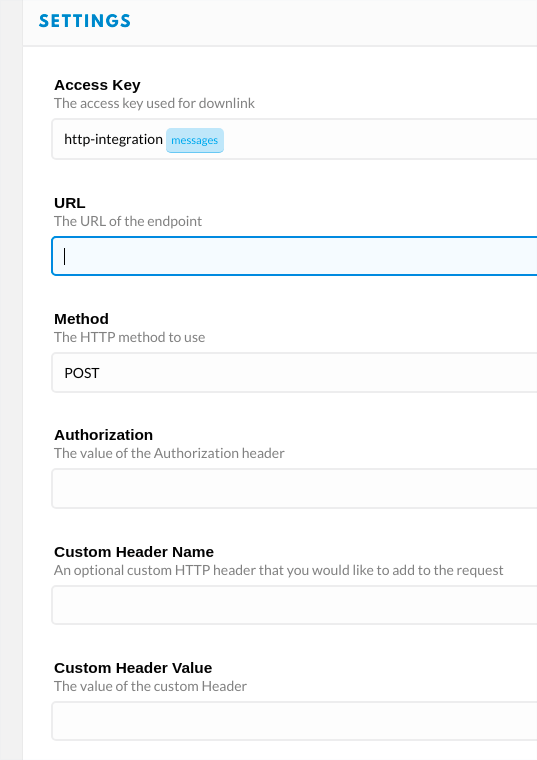
Weil sich auch @tonke gerade mit TTN beschäftigt, konnten wir hier ein weiteres TTN Datenpaket aufschnappen, das heute Vormittag über zwei Gateways gleichzeitig gelaufen ist:
{
"app_id": "{redacted}",
"dev_id": "{redacted}",
"hardware_serial": "{redacted}",
"port": 2,
"counter": 61,
"payload_raw": "oLsNQHcbU004qQY1EoYAWD4PWD4Pxo4P8KYd",
"payload_fields": {
"battery": 3.4322,
"cog": 0,
"hexstring": "160,187,13,64,119,27,83,77,56,169,6,53,18,134,0,88,62,15,88,62,15,198,142,15,240,166,29",
"latitude": 0,
"longitude": 0,
"pitch": -12.4887,
"pressure": 944.28,
"raw": "oLsNQHcbU004qQY1EoYAWD4PWD4Pxo4P8KYd",
"roll": 8.9811,
"speed": 0,
"temp": 20.59
},
"metadata": {
"time": "2019-02-08T10:02:39.405910743Z",
"frequency": 868.3,
"modulation": "LORA",
"data_rate": "SF7BW125",
"airtime": 82176000,
"coding_rate": "4/5",
"gateways": [
{
"gtw_id": "eui-{redacted}",
"timestamp": 513428579,
"time": "2019-02-08T10:02:39.381198Z",
"channel": 1,
"rssi": -107,
"snr": -4.5,
"rf_chain": 1,
"latitude": 47.000000,
"longitude": 11.000000,
"location_source": "registry"
},
{
"gtw_id": "eui-{redacted}",
"timestamp": 2307776099,
"time": "",
"channel": 1,
"rssi": -63,
"snr": 9.5,
"rf_chain": 1,
"latitude": 47.000000,
"longitude": 11.000000,
"altitude": 700,
"location_source": "registry"
}
]
}
}
Merci!
Da wir ja gerne möglichst umfangreiche Telemetriedaten erhalten wollen (stimmts?), finde ich diese Information sehr wertvoll, weil wir u.U. auch die Metadaten aller involvierten Gateways aufzeichnen wollen, wenn wir schon dabei sind.