Bei Phänologischer Kalender für Trachtpflanzen haben wir die Entwicklung eines komfortablen phänologischen Kalenders für Imker ins Auge gefasst.
Hier im Verlauf geht es konkret um das Programm »phenodata«, das auf dieser Basis entstanden ist.
Bei Phänologischer Kalender für Trachtpflanzen haben wir die Entwicklung eines komfortablen phänologischen Kalenders für Imker ins Auge gefasst.
Hier im Verlauf geht es konkret um das Programm »phenodata«, das auf dieser Basis entstanden ist.
Danke für Eure exzellenten Rückmeldungen bei Phänologischer Kalender für Trachtpflanzen!
Wir konnten die ersten Spatenstiche machen und Ihr könnt nun die Entwicklung begleiten, das Paket gibt es auf PyPI:
und den Quellcode auf GitHub:
pip install phenodata --upgrade
Was bereits funktioniert, ist:
Display list of species:
phenodata list-species --source=dwd
Display list of phases:
phenodata list-phases --source=dwd
Display list of stations:
phenodata list-stations --source=dwd --dataset=immediate
phenodata list-stations --source=dwd --dataset=annual
“phenodata 0.3.0” kann nun endlich Beobachtungen abrufen und rudimentär nach Stations-IDs und Referenzjahren filtern. Hier gschwind ein paar Beispiele:
phenodata observations \
--source=dwd --dataset=annual --partition=recent \
--filename=Hasel,Schneegloeckchen
phenodata observations \
--source=dwd --dataset=annual --partition=historical \
--filename=Hasel,Schneegloeckchen --station-id=164,717 --year=2016,2017
Weiterhin ist es nun möglich, aus einem der Ausgabeformate “tabulate”, “json” sowie “csv” auszuwählen, hier der entsprechende Auszug aus “phenodata --help”:
Data formatting options:
--format=<format>
Output data in designated format. Choose one of “tabulate”, “json” or “csv”.
With “tabulate”, it is also possible to specify the table format,
see https://bitbucket.org/astanin/python-tabulate. e.g. “tabulate:presto”.
[default: tabulate:psql]
Aufgrund mancher Anomalien in den Daten läuft bestimmt noch nicht alles rund, vor allem bei anderen Kombinationen der Parameter, wir testen das ja auch nur “auf unserer Insel”. Wenn Ihr also neugierig seid, damit bereits ein wenig Datenarchäologie zu betreiben, freuen wir uns über Eure Rückmeldungen.
“phenodata 0.4.0” berechnet nun auch Vorhersagen auf Basis von Mittelwerten beliebig gefilterter Observationsereignisse.
Zur Berechnung des voraussichtlichen Eintrittsdatums eines Ereignisses wird der Tag des Jahres aus der “Jultag” Spalte verwendet. Zuerst werden die Observationsereignisse nach (Stations ID, Spezies ID und Phasen ID) gruppiert, dann wird der Mittelwert aller “Jultag” Werte pro Gruppe gebildet. Haut das hin?
Anhand eines Beispiels sieht das folgendermaßen aus:
phenodata forecast \
--source=dwd --dataset=annual --partition=recent \
--filename=Hasel,Schneegloeckchen,Apfel,Birne \
--station-id=12132 \
--quality-byte=1,2,3 --quality-level=7,10 \
--format=markdown
| date | Jultag | |
|---|---|---|
| (12132, 113, 5) | 2018-02-19 00:00:00 | 50 |
| (12132, 127, 5) | 2018-02-17 00:00:00 | 48 |
| (12132, 311, 3) | 2018-04-01 00:00:00 | 91 |
| (12132, 311, 5) | 2018-04-23 00:00:00 | 113 |
| (12132, 311, 6) | 2018-04-30 00:00:00 | 120 |
| (12132, 311, 7) | 2018-05-13 00:00:00 | 133 |
| (12132, 311, 29) | 2018-08-17 00:00:00 | 229 |
| (12132, 311, 32) | 2018-10-23 00:00:00 | 296 |
| (12132, 313, 3) | 2018-04-12 00:00:00 | 102 |
| (12132, 313, 5) | 2018-05-03 00:00:00 | 123 |
| (12132, 313, 6) | 2018-05-10 00:00:00 | 130 |
| (12132, 313, 7) | 2018-05-25 00:00:00 | 145 |
| (12132, 313, 29) | 2018-09-28 00:00:00 | 271 |
| (12132, 313, 32) | 2018-11-03 00:00:00 | 307 |
| (12132, 322, 5) | 2018-04-15 00:00:00 | 105 |
| (12132, 322, 6) | 2018-04-26 00:00:00 | 116 |
| (12132, 322, 7) | 2018-05-11 00:00:00 | 131 |
| (12132, 322, 29) | 2018-09-22 00:00:00 | 265 |
In der ersten Indexspalte sind die durch die Gruppierung/Aggregation zusammengefassten ehemaligen Indexspalten Stations ID, Spezies ID und Phasen ID kombiniert enthalten.
Am Beispiel der ersten Aggregation (12132, 113, 5) erkennt man folgende Komponenten:
Stations ID: 12132 ist Berlin-Dahlem
Der Beobachtungsort.
Spezies ID: 113 ist die Hasel
Die beobachtete Pflanze.
Phase ID: 5 ist “Blüte Beginn” (BBCH 60)
Das beobachtete Ereignis, in welche Wachstumsphase die Pflanze eingetreten ist.
Die Zuordnung muss man derzeit noch händisch erforschen:
# List of stations
phenodata list-stations --source=dwd --dataset=immediate
# List of species
phenodata list-species --source=dwd
# List of phases
phenodata list-phases --source=dwd
Die Implementierung findet sich unter:
“phenodata 0.5.0” bietet neben anderen Dingen nun eine Option “--humanize”, die Ausgabe wird dadurch für Menschen besser lesbar.
Nach dem Abfragen der Ergebnisse werden sie mit den Metadatentabellen verknüpft, die die Informationen über die Stationen, die Spezies, die Phasen und die Qualitätsmerkmale enthalten. Dies ermöglicht die Darstellung der jeweiligen textuellen Repräsentationen der Informationen in den ID Spalten.
Anschließend wird ein komplett neuer DataFrame erzeugt, um die Reihenfolge der Spalten frei bestimmen zu können, damit wird die Ausgabe auch von der Struktur her besser lesbar.
Forecast of “beginning of flowering” events at station “Berlin-Dahlem”.
Use all species of the “primary group”: “hazel”, “snowdrop”, “goat willow”,
“dandelion”, “cherry”, “apple”, “winter oilseed rape”, “black locust” and “common heather”.
Sort by date, ascending.
phenodata forecast \
--source=dwd --dataset=annual --partition=recent \
--filename=Hasel,Schneegloeckchen,Sal-Weide,Loewenzahn,Suesskirsche,Apfel,Winterraps,Robinie,Winter-Linde,Heidekraut \
--station-id=12132 --phase-id=5 \
--humanize \
--sort=Datum \
--format=markdown
| Datum | Spezies | Phase | Station |
|---|---|---|---|
| 2018-02-17 | common snowdrop | beginning of flowering | Berlin-Dahlem, Berlin |
| 2018-02-19 | common hazel | beginning of flowering | Berlin-Dahlem, Berlin |
| 2018-03-30 | goat willow | beginning of flowering | Berlin-Dahlem, Berlin |
| 2018-04-07 | dandelion | beginning of flowering | Berlin-Dahlem, Berlin |
| 2018-04-15 | cherry (late ripeness) | beginning of flowering | Berlin-Dahlem, Berlin |
| 2018-04-21 | winter oilseed rape | beginning of flowering | Berlin-Dahlem, Berlin |
| 2018-04-23 | apple (early ripeness) | beginning of flowering | Berlin-Dahlem, Berlin |
| 2018-05-03 | apple (late ripeness) | beginning of flowering | Berlin-Dahlem, Berlin |
| 2018-05-24 | black locust | beginning of flowering | Berlin-Dahlem, Berlin |
| 2018-08-20 | common heather | beginning of flowering | Berlin-Dahlem, Berlin |
Forecast of all events at station “Berlin-Dahlem”.
Use all species of the “primary group” (dito).
Sort by species and date, ascending.
phenodata forecast \
--source=dwd --dataset=annual --partition=recent \
--filename=Hasel,Schneegloeckchen,Sal-Weide,Loewenzahn,Suesskirsche,Apfel,Winterraps,Robinie,Winter-Linde,Heidekraut \
--station-id=12132 \
--humanize --language=german \
--sort=Spezies,Datum \
--format=markdown
| Datum | Spezies | Phase | Station |
|---|---|---|---|
| 2018-04-01 | Apfel, frühe Reife | Austrieb Beginn | Berlin-Dahlem, Berlin |
| 2018-04-23 | Apfel, frühe Reife | Blüte Beginn | Berlin-Dahlem, Berlin |
| 2018-04-30 | Apfel, frühe Reife | Vollblüte | Berlin-Dahlem, Berlin |
| 2018-05-13 | Apfel, frühe Reife | Blüte Ende | Berlin-Dahlem, Berlin |
| 2018-08-17 | Apfel, frühe Reife | Pflückreife Beginn | Berlin-Dahlem, Berlin |
| 2018-10-23 | Apfel, frühe Reife | herbstlicher Blattfall | Berlin-Dahlem, Berlin |
| 2018-04-12 | Apfel, späte Reife | Austrieb Beginn | Berlin-Dahlem, Berlin |
| 2018-05-03 | Apfel, späte Reife | Blüte Beginn | Berlin-Dahlem, Berlin |
| 2018-05-10 | Apfel, späte Reife | Vollblüte | Berlin-Dahlem, Berlin |
| 2018-05-25 | Apfel, späte Reife | Blüte Ende | Berlin-Dahlem, Berlin |
| 2018-09-28 | Apfel, späte Reife | Pflückreife Beginn | Berlin-Dahlem, Berlin |
| 2018-11-03 | Apfel, späte Reife | herbstlicher Blattfall | Berlin-Dahlem, Berlin |
| 2018-02-19 | Hasel | Blüte Beginn | Berlin-Dahlem, Berlin |
| 2018-08-20 | Heidekraut | Blüte Beginn | Berlin-Dahlem, Berlin |
| 2018-04-07 | Löwenzahn | Blüte Beginn | Berlin-Dahlem, Berlin |
| 2018-05-24 | Robinie | Blüte Beginn | Berlin-Dahlem, Berlin |
| 2018-03-30 | Sal-Weide | Blüte Beginn | Berlin-Dahlem, Berlin |
| 2018-02-17 | Schneeglöckchen | Blüte Beginn | Berlin-Dahlem, Berlin |
| 2018-04-15 | Süßkirsche, späte Reife | Blüte Beginn | Berlin-Dahlem, Berlin |
| 2018-04-24 | Süßkirsche, späte Reife | Vollblüte | Berlin-Dahlem, Berlin |
| 2018-05-06 | Süßkirsche, späte Reife | Blüte Ende | Berlin-Dahlem, Berlin |
| 2018-06-21 | Süßkirsche, späte Reife | Pflückreife Beginn | Berlin-Dahlem, Berlin |
| 2018-10-09 | Süßkirsche, späte Reife | herbstliche Blattverfärbung | Berlin-Dahlem, Berlin |
| 2018-03-28 | Winterraps | Längenwachstum Beginn | Berlin-Dahlem, Berlin |
| 2018-04-06 | Winterraps | Knospenbildung Beginn | Berlin-Dahlem, Berlin |
| 2018-04-21 | Winterraps | Blüte Beginn | Berlin-Dahlem, Berlin |
| 2018-07-08 | Winterraps | Vollreife Beginn | Berlin-Dahlem, Berlin |
| 2018-08-11 | Winterraps | Ernte | Berlin-Dahlem, Berlin |
| 2018-08-31 | Winterraps | Bestellung Beginn | Berlin-Dahlem, Berlin |
| 2018-09-10 | Winterraps | Auflaufen Beginn | Berlin-Dahlem, Berlin |
| 2018-09-30 | Winterraps | Rosettenbildung Beginn | Berlin-Dahlem, Berlin |
– Have fun!
Mit “phenodata 0.6.0” ist es nun möglich
Observations near Munich for species “hazel” or “snowdrop” in 2022. Sort by date, output in Markdown format.
phenodata observations \
--source=dwd --dataset=annual --partition=recent \
--station=münchen \
--species=hazel,snowdrop \
--year=2022 \
--humanize --sort=Datum \
--format=markdown
| Jahr | Datum | Spezies | Phase | Station | QS-Level | QS-Byte |
|---|---|---|---|---|---|---|
| 2018 | 2018-01-09 | common hazel | beginning of flowering | München-Pasing, Bayern | Load time checks | Feldwert nicht beanstandet |
| 2018 | 2018-01-19 | common snowdrop | beginning of flowering | Haar, Bayern | Load time checks | Feldwert nicht beanstandet |
| 2018 | 2018-01-26 | common snowdrop | beginning of flowering | Siegertsbrunn, Bayern | Load time checks | Feldwert nicht beanstandet |
| 2018 | 2018-01-27 | common snowdrop | beginning of flowering | München-Pasing, Bayern | Load time checks | Feldwert nicht beanstandet |
| 2018 | 2018-02-03 | common hazel | beginning of flowering | Siegertsbrunn, Bayern | Load time checks | Feldwert nicht beanstandet |
| 2018 | 2018-02-16 | common hazel | beginning of flowering | Haar, Bayern | Load time checks | Feldwert nicht beanstandet |
Die Wunschlisten für relevante Pflanzenarten sind nun ebenfalls implementiert. Sie wurden, wie von Euch vorgeschlagen, in entsprechende Kategorien einsortiert und einstweilen direkt in der presets.json abgelegt.
Ansteuern/benutzen kann man sie über den neuen Parameter
--species-preset=mellifera-de-primary
Forecast based on “beginning of flowering” events of 2015-2017 in Rostock for the list of predefined species labelled as “mellifera-de-primary”. Sort by date, output in Markdown format.
Remark: The presets are currently stored in presets.json and can be amended and expanded anytime. We are looking forward to your contributions!
phenodata forecast \
--source=dwd --dataset=annual --partition=recent \
--station=rostock \
--phase="beginning of flowering" \
--year=2020,2021,2022 \
--humanize --language=german \
--sort=Datum \
--species-preset=mellifera-de-primary \
--format=markdown
| Datum | Spezies | Phase | Station |
|---|---|---|---|
| 2018-02-18 | Hasel | Blüte Beginn | Rostock-Lütten Klein, Mecklenburg-Vorpommern |
| 2018-02-21 | Schneeglöckchen | Blüte Beginn | Rostock-Lütten Klein, Mecklenburg-Vorpommern |
| 2018-03-20 | Sal-Weide | Blüte Beginn | Rostock-Lütten Klein, Mecklenburg-Vorpommern |
| 2018-04-01 | Löwenzahn | Blüte Beginn | Rostock-Lütten Klein, Mecklenburg-Vorpommern |
| 2018-04-18 | Süßkirsche, frühe Reife | Blüte Beginn | Rostock-Lütten Klein, Mecklenburg-Vorpommern |
| 2018-04-27 | Winterraps | Blüte Beginn | Rostock-Lütten Klein, Mecklenburg-Vorpommern |
| 2018-05-03 | Apfel, frühe Reife | Blüte Beginn | Rostock-Lütten Klein, Mecklenburg-Vorpommern |
| 2018-06-07 | Robinie | Blüte Beginn | Rostock-Lütten Klein, Mecklenburg-Vorpommern |
Es ist nun genauso möglich, bei datenarchäologischen Reisen komfortabel nach extravaganten Dingen im Volltext zu suchen. Zum Abschluß noch ein kleines Beispiel.
Investigate some “flowering” observations near Munich which have seen corrections in the last year.
phenodata observations \
--source=dwd --dataset=annual --partition=recent \
--station=münchen \
--phase=flowering \
--quality=korrigiert \
--humanize --sort=Datum \
--format=markdown
| Jahr | Datum | Spezies | Phase | Station | QS-Level | QS-Byte |
|---|---|---|---|---|---|---|
| 2017 | 2017-04-30 | midland hawthorn | beginning of flowering | Haar, Bayern | ROUTKLI validated and corrected | Feldwert korrigiert |
| 2017 | 2017-07-16 | common wormwood | beginning of flowering | München-Feldmoching, Bayern | ROUTKLI validated and corrected | Feldwert korrigiert |
| 2017 | 2017-07-31 | common wormwood | beginning of flowering | Haar, Bayern | ROUTKLI validated and corrected | Feldwert korrigiert |
pipe is also a nice option, tables generated using the --format=tabular:pipe option can be copied 1:1 in this forum and are rendered nicely:
pipefollows the conventions of PHP Markdown Extra extension. It corresponds topipe_tablesin Pandoc.
Edit: --format=tabular:pipe now has also been aliased to --format=markdown, or, even shorter, --format=md.
Ab dem aktuellen Release 0.9.1 wird nun auch Python 3 unterstützt, die Ergebnisse bei Phänologischer Kalender 2020 wurden mit Python 3.7.5 erzeugt.
phenodata-0.9.3 has just been released. It is essentially a maintenance release and should improve installation convenience on Python 3 by allowing more recent versions of Pandas to be used as a dependency.
In this manner, the chance is higher that respective binary wheel packages are available from PyPI, so pandas as well as NumPy packages will not have to be compiled on your workstation. This will save both time and resources when installing phenodata.
Apart from that, phenodata might also install flawlessly on Windows now because those dependencies are usually provided as *-win32.whl and *-win_amd64.whl binary wheel packages nowadays.
Just type:
pip install phenodata --user --upgrade
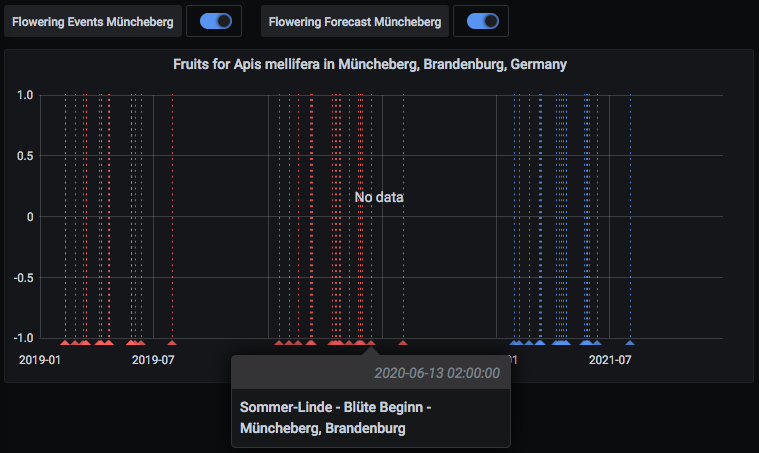
Das Beispiel “Apis mellifera flowering example” der GitHub - panodata/grafana-pandas-datasource: Grafana Python datasource - using Pandas for timeseries and table data zeigt einen Ausblick auf die Integration mit Grafana – siehe Phänologischer Kalender für Trachtpflanzen.
Mit phenodata-0.11.0 lassen sich die Daten nun auch zusätzlich ad hoc per SQL filtern.
pip install 'phenodata[sql]' --user --upgrade
phenodata observations \
--source=dwd --dataset=annual --partition=recent \
--year=2019,2020,2021,2022,2023 \
--species-preset=mellifera-de-primary --phase="beginning of flowering" \
--humanize --language=german \
--sql="SELECT * FROM data WHERE Station LIKE '%Berlin%' ORDER BY Datum" \
--format=markdown
9 posts were merged into an existing topic: Erweiterung von »phenodata« um Erträge von Futterpflanzen
Guten Tag. Hat eigentlich mal jemand versucht, ob das Programm auch dieses Jahr noch ordentlich funktioniert?
@weef meldete einige Fehler, vielen Dank. Das Programm hat jetzt endlich Softwaretests bekommen, das erleichtert die Wartung zukünftig deutlich.
Es sind noch weitere Verbesserungen in Vorbereitung, unter anderem Kompatibilität mit dem kürzlich veröffentlichten pandas 2.0 [1].
P.S.: Alarm Alarm. Derzeit scheinen keine Beobachtungen aus Berlin-Dahlem reinzukommen, das ganze Jahr schon nicht. Oder es gibt noch andere Bugs im Programm. Falscher Alarm: Berlin-Dahlem ist ein Jahresmelder (annual), und ich hatte nur bei den Sofortmeldern geschaut (immediate). Berlin-Dahlem liefert weiterhin treu, und bietet derzeit Daten u.a. von 2022 an.
phenodata 0.13.0 wurde veröffentlicht, korrigiert einige Probleme, und hat jetzt auch bessere Dokumentation. Ein Update auf die neueste Version klappt per:
pip install --upgrade 'phenodata[sql]'
Phenodata hat ein Subsystem bekommen, mit dem die erfassten Daten in SQLite Datenbanken exportiert werden können.
Die SQLite Datenbanken können dann in Folge z.B. per Grafana SQLite Datasource in der Grafana Domäne erschlossen werden, oder in jeder beliebigen anderen Anwendung auch, z.B. in b.tree oder BEEP.
Hi again,
I’ve just created two tickets to track the eventual inclusion of phenology observation data from other countries. Maybe you can discover corresponding resources to contribute. Thanks!
With kind regards,
Andreas.