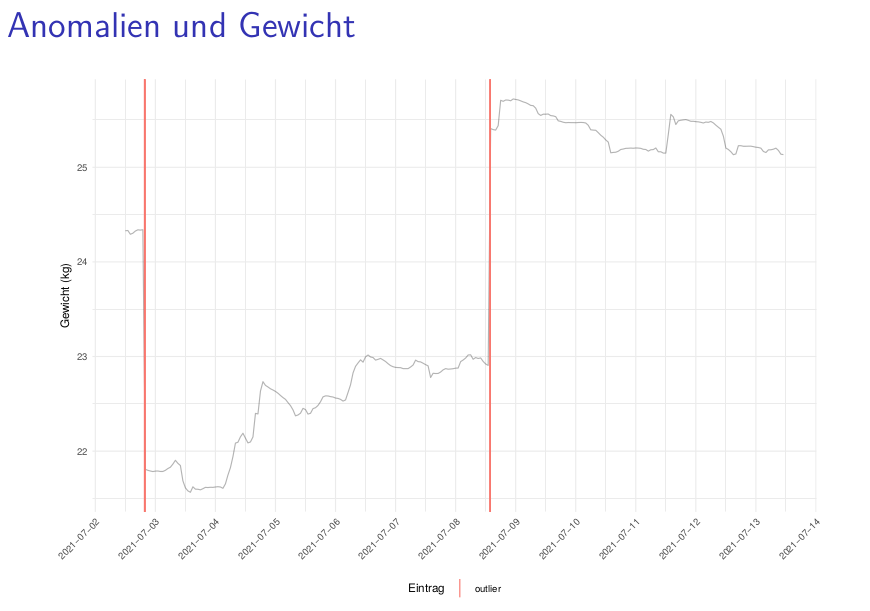
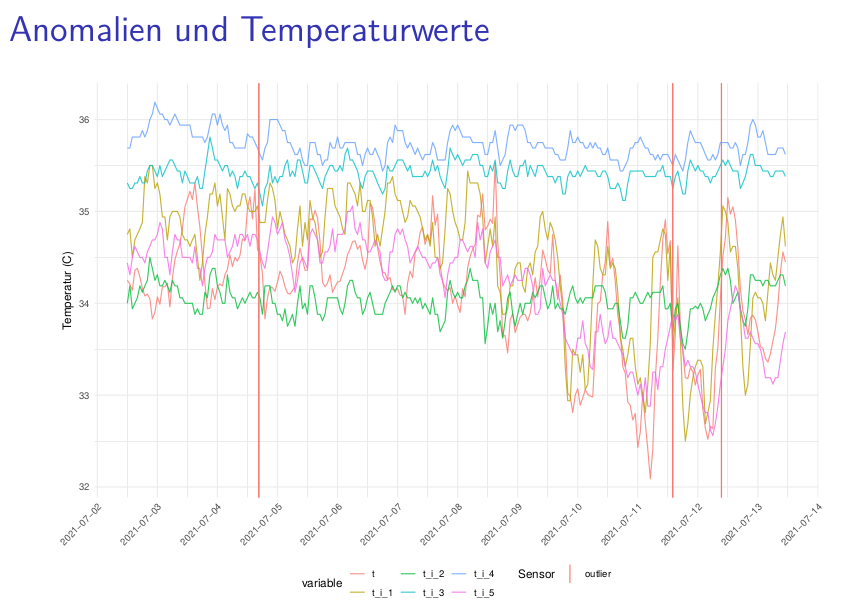
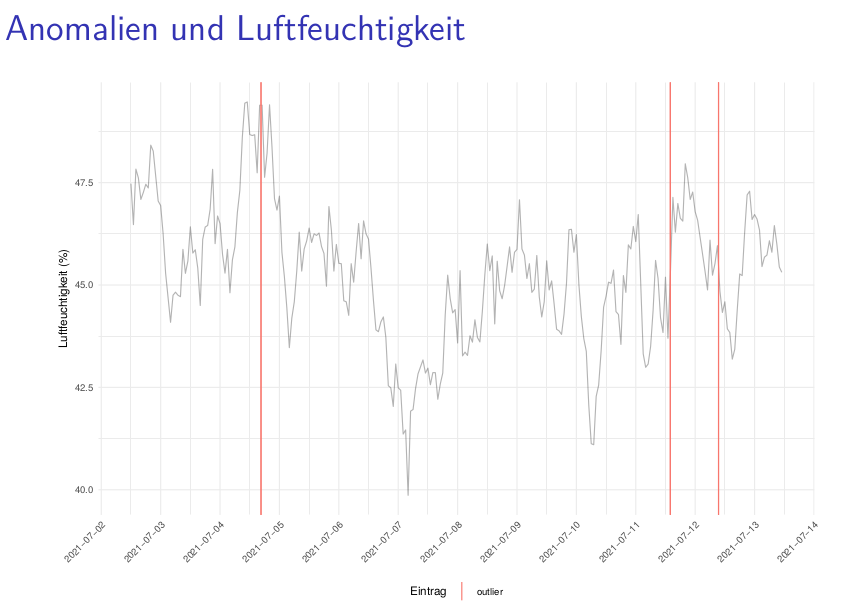
wir versuchen nun regelmäßig Berichte an alle Imkernde mit aktiver Sensor-Beute zu schicken. Dort kennzeichnen wir probeweise auch Anomalien. Später sollen diese Visualisierungen in die App eingebaut werden.
Zur Anomalieerkennung nutzen wir ein ARIMA-Modell, um Werte vorherzusagen. Weicht die Vorhersage stark von den eigentlichen Werten ab, kennzeichnen wir eine Anomalie.
Hier könnt ihr euch darüber austauschen. Einige offene Fragen sind zum Beispiel:
Wie viele Anomalien sollten gekennzeichnet werden? Denkt ihr, es wurden zu viele Anomalien gekennzeichnet?
Welche Ursachen könnten diese Anomalien haben?
Ich poste gleich noch Beispiele und verschicke neue Berichte.
Schon, das Du weiterhin bei dem Projekt dabei bist und die Daten auswertest.
Mir war leider gar nicht bewusst , das die Daten immer noch so akribisch auf Anomalie überprüft werden.
Ich hätte dann, sicher nicht den Fehler gemacht, den zusätzlichen Einbau eines saraswati-Knotens beim Bee-Observer zu Dokumentieren.
Bin mir aber auch nicht sicher, worunter ich das hätte eintragen sollen. Am ehesten sicher unter Flugloch
-Beobachtung.
Die gleiche Frage Stelle ich mir auch während anderen Arbeiten. z.B.Nachbarvolk Durchsicht - Stockmeißel/Handy abgelegt oder bei Sturm - Wetterschutzhaube runtergeweht/wieder aufgesetzt usw.
@Diren macht es Sinn, diese Daten zusätzlich zur E-Mail Antwort nachzutragen? Oder erzäugt das bei Euch mehr oder weniger Arbeit?
Bei Saraswati überlege ich mir außerdem eine Art Audio Stockkarte zu machen und bei der Durchsicht einfach zu erzählen, was ich sehe.
Genauere Benennung der Anomalien erfolgt natürlich per E-Mail. Ich bin mir nicht sicher ob hier öffentlich die Sensor-ID für die Zuordnung genannt werden sollte.
Edit: Beim analysieren der Anomalien ist es mir schwer gefallen die Urzeiten und Daten einem bestimmten Ereignis /Sensor / Datensatz zuzuordnen. Die Zeitangabe müsste UTC sein richtig? Es ist sehr schwer die Anomalien in Bee-Observer.org oder swarm.Hiveeyes.org zu finden, da die Anomalien dort anscheinend auch teilweise rausgefiltert oder gemittelt werden.
Wenn man nicht schon vorher sowieso eine Idee hat, ist es nahezu unmöglich.
Etwas mehr Informationen über die Anomalien wär daher Wünschenswert, wenn es technisch überhaupt machbar ist.
Genau solche Überlegungen, sind das, was wir gerade brauchen! Wir denken darüber nach, wie denn so eine Abfrage in der App in Zukunft aussehen sollte.
“Inspektion Nachbarvolk” könnte eine häufig genutzte Kategorie werden, Wetterschutzhaube o.ä. klingt auch sinnvoll, wenn auch vielleicht seltener?
Für den Moment schon. Wir haben auch schon überlegt diese Liste zu ergänzen oder zu verändern.
Ja, sehr gerne, würde helfen!
Kommt in Zukunft hoffentlich, wenn wir das so hinkriegen, wie wir uns das vornehmen. Bisher können wir nur die Visualisierungen in den Berichten anbieten.
Die Zeitangabe in den Berichten sollte Europäische Sommerzeit sein, wenn ihr Ungereihmtheiten findet, sagt Bescheid!
vielen herzlichen Dank für die Vorstellung und Anregung zum Austausch, auch für Deinen Vortrag zum Thema.
Schade dass dort bisher niemand geantwortet hat, scheinbar ist das allgemeine Interesse an diesen Themen doch nicht so hoch, zumindest hier im Forum? Ich hoffe Du hast anderweitig positive Resonanz dazu erhalten, ansonsten würde ich das an dieser Stelle gerne noch einmal nachholen , und die Gelegenheit ergreifen, unsere Gedanken dazu beizusteuern.
Haben sich denn bei Euch weitere Neuigkeiten zum Thema ergeben? Arbeitet Ihr noch aktiv daran?
Wunderbar, wenn das gut klappt. Im Vortrag haben wir auch noch DTW aufgeschnappt, für die Schwarmerkennung? Läuft das separat, oder kombiniert Ihr beide Methoden?
Wir hätten so ein Subsystem ja seit jeher schon gerne (auch) in Kotori implementiert, damit entsprechende Anwendungsfreundlichkeiten auch Wissenschaftler:innen anderer Forschungsfelder zur Verfügung stehen können, die gerne mit Zeitseriendaten hantieren. Offiziell haben wir das aber bislang noch nie mit Euch ausgelotet, daher vielleicht nun: Wie sind hierzu Eure Meinungen und Interessenslagen?
Finde ich eine super Idee mit allgemeinen Modellen und generischen Ansätzen hier weiter zu gehen. Wir sind ja weder bei BOb noch bei hiveeyes zu (Bienen-)spezifischen Modellen gekommen, da wir einfach zu wenige annotierte Trainingsdaten haben. Anomalien sind überall und in allen Daten wichtig, ich glaube auch @Diren hat versucht mit einer anomaly detection Schwärme zu detektieren.
Vielleicht gibt es auch Anomalien in Sounddaten, wenn die Asiatische Hornisse ein Volk massiv bedrängt o.ä. Sprich, wir könnten hier zumindest schon einen (technischen) Hinweis bekommen “da stimmt was nicht” und dann im nächsten Schritt schauen, was es ist und die Daten um das Anomalie-event genauer anschauen, mit anderen Anomalie-Ereignissen vergleichen und ggf. kategorisieren.
Im besten Fall unterscheiden sich die events dann signifikant und man hätte praktisch verwertbare Kategorien: Anomalie-Schwarm, Anomalie-weisellos, Anomalie-(fast)-verhungert.
So was webbasiert oder in Grafana zu haben wäre auch super, einfach weil die Lernkuve über R oder andere Statistik-Interfaces für viele zu steil ist.