A post was merged into an existing topic: Dokumentechte Ausgabeformate über die Druckfunktion des Browsers erzeugen
 Motivation: Create hardcopy-like documents from Discourse content easily
Motivation: Create hardcopy-like documents from Discourse content easily
Basic research
- Format for hard copy or PDF printing - feature - Discourse Meta
- Pocket (offline reader) support - feature - Discourse Meta
- Printer Friendly CSS - ux - Discourse Meta
- Add a get-option to enable noscript view of a page - feature - Discourse Meta
- Print long topic to PDF, redux, again - feature - Discourse Meta
- Making DOI Ready PDFs from Discourse - feature - Discourse Meta
- Converting links from raw markdown to HTML - dev - Discourse Meta
- Creating an offline topic reading archive - ux - Discourse Meta
Evaluation am Beispiel
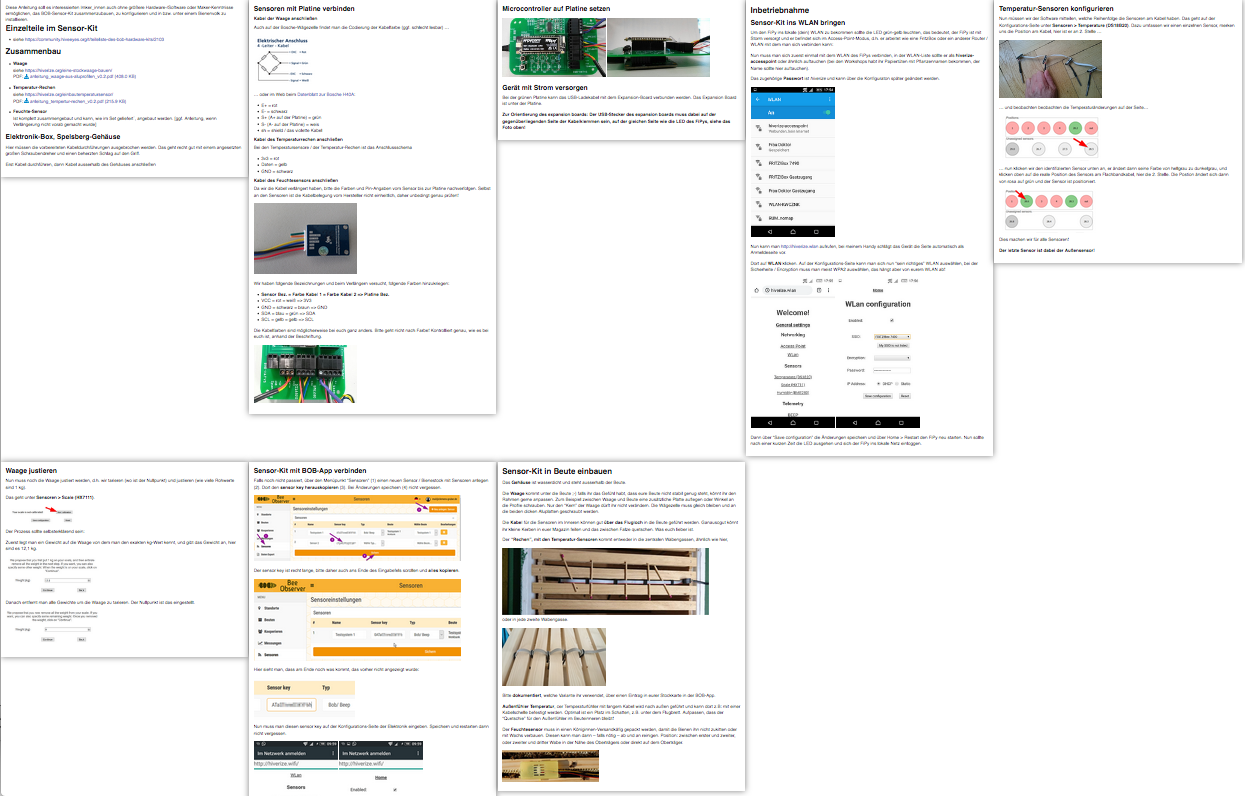
Für das Bee Observer Projekt wollen wir gerne einige bereits vorbereitete Ressourcen in Papierform bringen. Als kanonisches Beispiel verwenden wir dafür die Beiträge bei Aufbau und Installation des Bee Observer Sensor-Kits (grüne Platine).
-
So bekommt man aus der JSON Repräsentation [1] den fertig nach HTML gerenderten Inhalt (im Fachjargon “cooked”) eines Posts – ganz ohne CSS.
http --follow 'https://community.hiveeyes.org/t/anleitung-aufbau-und-installation-des-sensor-kits-grune-platine/2443.json?include_raw=true' | jq -r '.post_stream.posts[0].cooked' > 2443.cooked.html- Download: 2443.cooked.html (31.9 KB)
-
Das ist eine leicht händisch aufgemöbelte Variante mit CSS im Seiten-Look. Obacht, das sind keine echten DIN A Seiten o.ä., daher ist auch jenes nur bedingt fürs Drucken geeignet.
- Web: Anleitung, Aufbau und Installation des Sensor-Kits
- Download: 2443.cooked-with.css.html (33.5 KB)
-
Das ist Variante 2. dann als per “Firefox » Save Page As » Web Page, complete” gespeichert und anschließend in ein Zip-Archiv gepackt.
- Download: Anleitung, Aufbau und Installation des Sensor-Kits.zip (770.5 KB)
P.S.: Bei keinem dieser Varianten scheint das TOC durchzukommen.
Discourse Markdown in verschiedene Formate konvertieren
Einleitung
Mit dem Gedanken, über pandoc Konnektivität zwischen der Discourse-Domäne und der TeX-Domäne herzustellen, um sich damit geschickt ohne nennenswerte Aufwände aus der Affäre ziehen zu können, ging ich schon länger schwanger.
Hier habe ich ein paar erste kurze Versuche gewagt, das Original-Markup (Markdown) optimal weiterzuverarbeiten.
Beispiele
#!/bin/bash
# Acquire Markdown of single post.
# https://meta.discourse.org/t/discourse-api-documentation/22706/161
title="Anleitung, Aufbau und Installation des Sensor-Kits"
markup=$(http --follow 'https://community.hiveeyes.org/t/anleitung-aufbau-und-installation-des-sensor-kits-grune-platine/2443.json?include_raw=true' | jq -r '.post_stream.posts[0].raw')
echo "$markup" > 2443.md
# Convert Markdown to other formats.
pandoc 2443.md --standalone --from=markdown --metadata title="$title" --output 2443.pdf
pandoc 2443.md --standalone --from=markdown --metadata title="$title" --output 2443.html
pandoc 2443.md --standalone --from=markdown --metadata title="$title" --output 2443.epub
Zwischenfazit
Das Markdown bräuchte noch zusätzliche Massage, z.B. Ergänzung der Links zu Bildern, bevor da etwas anständiges herauszuholen wäre. Das sieht man ganz schnell, wenn man das selbst einmal versucht.
Ausblick
Besser mal das Cooked HTML ausprobieren, das Discourse bereits aus sich heraus pro Post zur Verfügung stellt.
Discourse cooked HTML anyone?
Hier versuchen wir, mit pandoc die von Discourse bereitgestellten vorgekochten HTML-Fragmente als Basis für die Transformation in andere Formate zu verwenden. TLDR; Klappt ganz gut.
Vorbereitung
# HTML beschaffen
http --follow 'https://community.hiveeyes.org/t/anleitung-aufbau-und-installation-des-sensor-kits-grune-platine/2443.json?include_raw=true' | jq -r '.post_stream.posts[0].cooked' > 2443.cooked.html
# Titel bestimmen
title="Anleitung, Aufbau und Installation des Sensor-Kits"
PDF erstellen
pandoc 2443.cooked.html --standalone --metadata title="$title" --table-of-contents --output "$title.pdf"
Anleitung, Aufbau und Installation des Sensor-Kits - pandoc.pdf (818.7 KB)
ODT erstellen
pandoc 2443.cooked.html --standalone --metadata title="$title" --table-of-contents --output "$title.odt"
Anleitung, Aufbau und Installation des Sensor-Kits.odt (702.1 KB)
EPUB erstellen
pandoc 2443.cooked.html --standalone --metadata title="$title" --output "$title.epub"
Anleitung, Aufbau und Installation des Sensor-Kits.epub (700.4 KB)
PDF aus EPUB erstellen
Mit https://calibre-ebook.com/.
Anleitung, Aufbau und Installation des Sensor-Kits.pdf (804.8 KB)
1 Like
Discourse cooked HTML in andere Dokumentformate konvertieren
Introducing the discodoc program…
About
The discodoc program offers effortless document generation from Discourse content. Its main workhorse is pandoc, the universal document converter.
Synopsis
# Generate PDF document from all posts of given topic.
discodoc https://community.hiveeyes.org/t/anleitung-aufbau-und-installation-des-sensor-kits-grune-platine/2443 --format=pdf
For advanced command line options, please invoke "discodoc --help" or visit the discodoc usage documentation.
Features
All output formats are provided by pandoc fame. These have been tested:
pdf, docx, odt, pptx, epub2, epub3, fb2, latex, texinfo, html, html5, json, plain, rtf, revealjs, s5.
Details
Die ersten Ergebnisse dieser Renderings sehen nicht schlecht aus – vor allem aus der Perspektive, dass dieser Vorgang vollständig automatisierbar Dokumente ausspucken kann.
Neben dem klassisch-kanonischen PDF-Ausgebeformat ist auch das HTML-Ausgabeformat praktisch, weil pandoc hier die undankbare Aufgabe per resource-inlining ein self-contained Bündel zu erzeugen, ganz hervorragend ausführt.
Auch die Presentation-/Slideshow-Renderings können sich sehen lassen, also z.B. LaTeX/Beamer oder HTML/S5 bzw. HTML/Reveal.js – aber auch .pptx.
Ausblick
Wenn man es auf dieser Basis noch edler haben will, exportiert man die Inhalte z.B. im .odt-Format oder wenn es unbedingt sein muss auch im .docx-Format und schnippelt noch ein wenig dran rum, z.B. im Bereich von Formatvorlagen (Header- und Footer mit Organisationslogo/-branding/-CI) oder bei der manuellen Nachjustage von Seitenumbrüchen. Voilà.
Um bei den Presentation-/Slideshow-Formaten out-of-the-box optimale Ergebnisse zu erzielen, kann man dieses potentielle Ziel entweder bereits ein wenig bei der Beitragsgestaltung berücksichtigen [1], oder eben über das .pptx-Format gehen und dann noch im Impress oder Powerpoint entsprechend manuell nacharbeiten.
-
Die Beiträge (Posts) sollten für angestrebte Slideshows nicht zu lang werden, da sie schließlich auf A4 quer passen müssen – dadurch wird der Inhalt recht schnell geclipped, da der (Auto-)Layout-Mechanismus slideshow-getreu großzügig arbeitet; schließlich wollen auch die Leute aus der letzten Reihe ohne Brille noch die Bullet-Points lesen… Manchmal ;]. ↩︎
1 Like
Habe den ODT-Export heute gleich testen dürfen, da vom BOB-Projekt die Anforderung nach einem bearbeitbaren und druckbaren Dokument kam. War zwar nicht hübsch, grob aber ok. An folgenden Aspekten habe ich händisch korrigierend nachgearbeitet:
- Bilder hatten umlaufenden Text.
- Die Dateinamen im Text sind unnütz, wenn sie wie hier z.B. einfach nur
screenshot-xlauten. - Einige Bilder überlagerten sich im Dokument.
Aber weniger Arbeit als ganz von Hand aus PDF kopieren und in Word oder anderswo einfügen ist es allemal!
1 Like
Klar.
Wenn man es auf dieser Basis noch edler haben will […] und schnippelt noch ein wenig dran rum.
Danke vielmals für die Bestandsaufnahme. Genauso klar, dass man da für die populärsten Schnitzer ggf. noch nen automatischen Postprocessing-Task dranhängen könnte, der noch einmal drüberschmirgelt.
Dieses “grob” ist nichts anderes als die Aufrechterhaltung und passabel-korrekte Umsetzung der kompletten Dokumentstruktur, die für eine weitere Überarbeitung das Rückgrat eines jeden Dokuments darstellt.
Dank der Mächtigkeit und Flexibilität von pandoc bekommen wir diese Strukturinformation ganz passabel ohne selbst zu implementierende Konvertierungen von einer Dokumentformatdomäne in eine andere – hier konkret aus dem cooked HTML von Discourse à la <h1><h2><h3>... nach whatever pandoc can do for us.
Dafür wars gedacht. Schön! Das Werkzeug spart - gerade bei wiederholten Iterationen - wirklich eine ganze Menge Arbeit. Zumindest habe ich das gehofft – daher freue ich mich über viele Einsatzzyklen dieses Werkzeugs [1], um den Grauen Herren…
Weitere Ideen und Wünsche dazu sind natürlich ebenso gerne gesehen, auch wenn sie vermutlich bis auf weiteres im Backlog landen werden. ↩︎
Backlog
- Automatische Erzeugung eines Inhaltsverzeichnisses – Table of Content (TOC).
- Automatische Erzeugung von self-contained Dokumenten (z.B. HTML).
- Mehrere Topics in einem Rutsch verarbeiten, um Dokumenserien sowie kombinierte Dokumente zu erzeugen.
- Gestaltung des Aussehens per CSS.
- Gestaltung der Header- und Footer-Bereiche pro Ausgabeseite.
- Das erzeugte Dokument um ein Deckblatt oder Anhänge ergänzen.
- More at the discodoc backlog.
Beim Rendern von S5-Slides (--format=html --renderer=s5) glaubte ich feststellen zu können, dass der Transformationsvorgang Seitenumbrüche berücksichtigt, wenn sie hier im Markdown per horizontal ruler --- ausgezeichnet wurden.
Drüben bei [INDEX] Dokumentation für Bee Observer Nachbau haben wir vier für Bee Observer relevante Dokumente identifiziert und deren Inhalte entsprechend verarbeitet und PDF Dateien daraus produziert.
Wollte das gerade mal testen, bekomme aber
root@XPS13-CGruber:~# http 'https://community.hiveeyes.org/t/anleitung-aufbau-und-installation-des-sensor-kits-grune-platine/2443.json?include_raw=true' | jq -r '.post_stream.posts[0].cooked' > 2443.cooked.html
parse error: Invalid numeric literal at line 1, column 16Please add the --follow parameter to the HTTPie call. Thanks!
$ http 'https://community.hiveeyes.org/t/anleitung-aufbau-und-installation-des-sensor-kits-grune-platine/2443.json?include_raw=true'
HTTP/1.1 301 Moved Permanently
Cache-Control: no-cache, no-store
Connection: keep-alive
Content-Type: text/html; charset=utf-8
Date: Wed, 16 Oct 2019 14:33:15 GMT
Location: https://community.hiveeyes.org/t/aufbau-und-installation-des-bee-observer-sensor-kits-grune-platine/2443.json
<html><body>You are being <a href="https://community.hiveeyes.org/t/aufbau-und-installation-des-bee-observer-sensor-kits-grune-platine/2443.json">redirected</a>.</body></html>
ah, da hängt es, Danke!
Ja. discodoc nimmt den Redirect aber scheinbar bereits automatisch mit, besser wäre also:
discodoc https://community.hiveeyes.org/t/anleitung-aufbau-und-installation-des-sensor-kits-grune-platine/2443
root@XPS13-CGruber:~# discodoc https://community.hiveeyes.org/t/anleitung-aufbau-und-installation-des-sensor-kits-grune-platine/2443 --format=pdf
Traceback (most recent call last):
File "/usr/local/bin/discodoc", line 6, in <module>
from discodoc.cli import run
File "/usr/local/lib/python2.7/dist-packages/discodoc/cli.py", line 9, in <module>
from discodoc.core import DiscodocCommand
File "/usr/local/lib/python2.7/dist-packages/discodoc/core.py", line 58
'created at {created_at} "{abstract}..."'.format(**post, abstract=abstract))
^
SyntaxError: invalid syntax
… hmmm …
You should use a more recent version of Python here. Python3.7 will probably be the best choice.
Ich habe in /usr/local/lib python2 und python3, pip läuft wohl mit python2, um python3 zu nutzen habe ich jetzt pip3 installiert. Vielleicht statt pip install discodoc in discodoc · PyPI pip3 install discodoc schreiben, damit klar ist, dass python 3 verlangt wird.
siehe auch python - How to install python3 version of package via pip on Ubuntu? - Stack Overflow
wird aber auch nicht besser
root@XPS13-CGruber:/usr/local/lib# discodoc http://community.hiveeyes.org/t/anleitung-aufbau-und-installation-des-sensor-kits-grune-platine/2443 --format=pdf
2019-10-16 18:02:52,797 [requests.packages.urllib3.connectionpool] INFO : Starting new HTTP connection (1): community.hiveeyes.org
2019-10-16 18:02:52,882 [requests.packages.urllib3.connectionpool] INFO : Starting new HTTPS connection (1): community.hiveeyes.org
2019-10-16 18:02:53,272 [discodoc.core] INFO : Collecting posts from topic #2443 "Aufbau und Installation des Bee Observer Sensor-Kits (grüne Platine)" created at 2019-08-10T21:11:50.830Z
Traceback (most recent call last):
File "/usr/local/bin/discodoc", line 11, in <module>
sys.exit(run())
File "/usr/local/lib/python3.5/dist-packages/discodoc/cli.py", line 102, in run
results = command.run()
File "/usr/local/lib/python3.5/dist-packages/discodoc/core.py", line 108, in run
self.run_sequential()
File "/usr/local/lib/python3.5/dist-packages/discodoc/core.py", line 124, in run_sequential
self.render_topic(url, filename_prefix=filename_prefix)
File "/usr/local/lib/python3.5/dist-packages/discodoc/core.py", line 140, in render_topic
topic.fetch()
File "/usr/local/lib/python3.5/dist-packages/discodoc/core.py", line 56, in fetch
abstract = post['raw'][:50].replace('\n', ' ')
KeyError: 'raw'
auf python 3.7 updaten?!?
bekomme unter WSL
python3 is already the newest version (3.5.1-3).
Eine zu kleine Python-Version (3.5 statt 3.7) kann hier eine Rolle spielen, es sieht für mich jedoch an dieser konkreten Stelle danach aus, dass auch hier dem Redirect nicht ordentlich gefolgt wird.
Das sollte eigentlich mit der aktuellen Version der requests Bibliothek gut funktionieren, siehe requests – Redirection and History. Vielleicht ist bei Dir aus irgendwelchen Gründen noch eine ältere installiert und Du kannst innerhalb des virtualenv per pip3 install requests --upgrade für Abhilfe sorgen.
P.S.: Vielleicht wollen wir auch diese Diskussion analog zu Missing data of my luftdaten sensor on the Grafana map und Hello from a group of Italian citizens interested in environment and environmental measurements rüber zu https://community.panodata.org/ verlagern? Bei Gelegenheit ;]
root@XPS13-CGruber:~# discodoc http://community.hiveeyes.org/t/anleitung-aufbau-und-installation-des-sensor-kits-grune-platine/2443 --format=pdf
2019-10-16 18:49:49,754 [discodoc.core] ERROR : Failed requesting URL "http://community.hiveeyes.org/t/anleitung-aufbau-und-installation-des-sensor-kits-grune-platine/2443.json?include_raw=true&print=true". The response was:
{"errors":["You’ve performed this action too many times, please try again later."]}
Haha, auch dem Server reicht es langsam! ;-)