Andreas und Richard haben ja schon schön die OSBH-Sound-Analyse angepasst, diese parametrisiert und so recht “usable” gemacht. Allerdings muss man es immer noch selbst auf einem Linux-Rechner installieren, was noch Probleme macht. Mit einem Debian Paket wird es zwar einfacher, aber man muss es immer noch installieren und zumindest einen RasPi / Linux-System / Server haben.
Könnten wir dafür nicht einen kleinen browserbasierten Webservice anbieten über den man Audio-Daten hochladen kann und dann wird das Analyse-Ergebnis ausgegeben und der Imker kann so recht einfach unseren Service testen, bekommt interessante Ergebnisse und wir könnten dabei fragen, ob wir die Audio-Daten “nachnutzen” können - zur Verbesserung des Kategorisierungs-Algorithmus?
Das wäre ein erster Schritt in Richtung BOB / Uni Bremen und auch auf nicht so technikaffine Imker zu.
Die Aufnahme sollte technisch recht einfach möglich sein, da moderne Beuten einen Gitterboden besitzen. Man müsste nur “Aufnahme” drücken, das Handy unter den Gitterboden halten / mit der Varroa-Schublade unterschieben und eine Minute warten und hätte so die Aufnahme.
Danach geht der Imker per Browser (oder später App) z.B. auf beelistener.hiveeyes.org und kann da die Audio-Datei hochladen.
Im Idealfall füllt sie / er einen kleinen Bogen zum Zustand des Volkes aus, diese Daten könnte man später zum Training des Algorithmus verwenden und zu einer digitalen “Stockkarte” ausbauen.
Nun wird serverseitig die Datei analysiert und der berechnete Status ausgegeben.
Ggf. wird die Audio-Datei und der dazugehörige Datensatz in unsere Datenbank aufgenommen.
Damit könnten wir schon jetzt den Imkern eine kleine interessante Spielwiese bieten, ohne dass sie sich irgendwas in die Beute einbauen müssen. So könnten wir probieren, ob die Stockkarte so funktionieren könnte und die Kategorien passen und verstanden werden und würden parallel Soundsamples für eine spätere Analyse sammeln.
zur Verfügung gestellt werden und damit die Möglichkeit bieten, Audiosamples komfortabel über eine Webseite hochladen und die Analyseergebnisse schöner darstellen zu können.
Coole Idee Clemens, dann machen viele mit, es gibt viele Daten zu korrelieren und das verbessert die Analyse. Allerdings werden auch neue Themen auftauchen, nicht-technische Benutzer können uns ganz schön fordern, verschiedene Endgeräte, verschiedene Apps, also, es ist auch eine Herausforderung die Platform zu öffnen, Grüsse, Markus
I sometime use inotify-wait (inotify-tools), watching change in a directory.
It allow to launch a script, using filename as argument when a file is created.
We use it to allow some privilege users to upload (sftp) xml files in order to import products data from PIM to eCommerce platform and distinguish web server process to import one.
The sound file upload process can be handle by webserver, then inotify could launch the analyze, storing result somewhere and make a report.
By doing so, there’s no need to decouple the processing steps using an external tool. The heavy processing step of audio analysis will be decoupled from the web server request/response cycle by running it asynchronously in a separate thread. The thread pool management will be controlled by Twisted and thimble, which we already use for performing MQTT message processing using a dedicated thread pool, a change we introduced to improve concurrency behavior the other day.
On the other hand, using inotify could be an interesting option for improving the standalone operation of “audiohealth” itself, which will be here to stay besides being introduced as an additional dependency to Kotori. We are happy to receive pull requests on GitHub (even when it’s only about documentation) for a use case where incoming audio samples will be handed over to the program invocation of audiohealth by a cool one-liner using inotify. Go ahead!
I won’t say it’s easier, but we have platform-gradeness as an overall goal. To get there, we aim at an integrated, robust solution like the other infrastructure parts we already run in production. Amongst other things, this is possible using the powerful Twisted framework offering all tooling required for writing such a piece of software, which contains multiple services and provides primitives for both multithreaded and asynchronous programming.
You are welcome, just keep on asking. We are always happy to share more insights about the overall design process of our infrastructure.
@einsiedlerkrebs and @andreas discussed some possibilities about which infrastructure components to add to our software stack to fulfill the requirements regarding media file and metadata storage, archival and retrieval. On top of that, we would be able to build the “Audioanalyse” web service as well as a general “Stockkarte” subsystem and more without having to reinvent the wheel in too many details.
Proposal
We want to use Kinto, a generic JSON document store with sharing and synchronisation capabilities. For getting more into the details, please have a look at its documentation, especially the overview page. Kinto is backed by Mozilla, where it is used in production already:
Kinto is used at Mozilla and released under the Apache v2 licence.
At Mozilla, Kinto is used in Firefox for global synchronization of frequently changed settings like blocklists, and the Web Extensions storage.sync API. It is also used in Firefox for Android for A/B testing and delivering extra assets like fonts or hyphenation dictionaries.
We have been following the development of Kinto from its roots in Cornice and Cliquet since 2015 and are reasonably convinced it suits our needs very well. We already used Cornice and Pyramid in some web application development projects in the past, so we are familiar with these infrastructure components and their subsystems under the hood.
Example media file upload API
As you can see from some bits of documentation, the media file upload API is not far away from our proposed API specification above:
Original specification
http \
--form POST \
https://swarm.hiveeyes.org/api/hiveeyes/testdrive/area-42/node-1/item \
audio@${wavfile} time=${timestamp} has_queen=yes
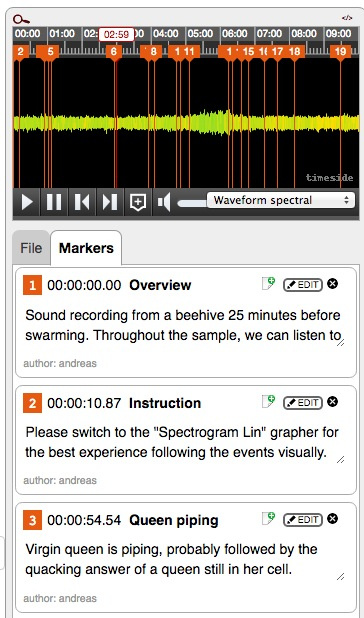
We actually evaluated Telemeta, installed an instance, uploaded and annotated some audio data (see https://telemeta.hiveeyes.org/archives/corpus/). The “Marker” feature to annotate audio samples interactively is pretty cool:
But we both like the idea of API-first driven development, built on top of modern software components. While Telemeta was my favorite candidate before, i like the discrete approach better now, which also better fits our overall system design philosophy. And @einsiedlerkrebs also convinced me somehow… :-).
The whole Telemeta system is way more heavy than the lightweight API-only approach using Kinto. Maybe we will embed the TimeSide component into the user interface after nailing down the API. In fact, this was my favorite component of Telemeta and already bundles all the audio-processing and -analysis stuff.
We are happy to hear your opinion and whether you have any objections regarding the current proposal. As i really like some specific features from Telemeta/TimeSide, it’s not completely from the table yet.
I have replied on the OSBH posting and made suggestions how to improve the upload and bundle it with a first analysis, so beekeeper get some “incentives” for providing data to the project:
Thanks for uploading your sound file to improve OSBH
OSBH Analysis Output
File: samples/colony-with-queen-gruber.wav.dat
Strategy: dt-1.0
==================
Sequence of states
==================
active, active, active
===================
Compressed timeline
===================
0s - 30s active ===
==============
Total duration
==============
30s active ===
Your Sound as Visualization:
It looks really great!
The Power Spectrum:
You have peaks around 100 Hz and 250 Hz!
Some Statistics:
Samples read: 3432960
Length (seconds): 38.922449
Scaled by rms: 0.002571
Maximum amplitude: 7.352207
Minimum amplitude: -5.996453
Midline amplitude: 0.677877
Mean norm: 0.770147
Mean amplitude: 0.020792
RMS amplitude: 1.000000
Maximum delta: 4.270675
Minimum delta: 0.000000
Mean delta: 0.172402
RMS delta: 0.230643
Rough frequency: 1618
Volume adjustment: 52.910
Just for the records: We just stumbled across “Django Filer”, which could also be a viable alternative for the file management part of the audio archival and -analysis web service. See its documentation, source code and an associated tutorial.
However, adding metadata fields to media items obviously requires changes to the source code including a database migration step. This is why we still would prefer a solution based on Kinto, which promises hassle-free, self-service operations offering the possibility to let the database schema being collaboratively evolved by the community in the spirit of a Folksonomy.
Have you seen the buzzbox announcement, they have a stand alone audio analyzing app now:
from the newsletter:
Download Our Free App
Tap the buttons below to download the OSBeehives app and analyse hive health from your phone, even without a BuzzBox sensor!
That’s really fun because we made some proposal – see this thread here ;-) – to realize this a good half year ago! Great news @Aaron and @Tristan_OSBH!!
… I was about to complain, that there is no (new) code on github, again.
But no need for that, since the name of this project company is silently changing:
Internet Archive's Wayback Machine
Loading...
https://www.opensourcebeehives.com |
15:56:39 March 19, 2018
Got an HTTP 301 response at crawl time
Redirecting to...
https://www.osbeehives.com/
Yeah, looks like OSBH is going commercial. That’s not a bad thing on its own, but it’s really sad that there’s no open source software released by them any more. Maybe they also switched the GitHub organization and just didn’t announce it yet?
Do you have any news, @Aaron or @Tristan_OSBH? We would really feel sad if we would lose you to corporate completely!