Spezifikation der HTTP Schnittstelle
Dies ist ein Vorschlag, wie eine flexible HTTP Schnittstelle für solche Zwecke gestaltet sein könnte.
Upload
Als mögliche Antwort des Aufrufs wäre u.U. folgendes denkbar:
HTTP/1.1 201 Created
Content-Type: text/uri-list
https://swarm.hiveeyes.org/item/hiveeyes/3b57fcef938b27846d262c83c0f574f8015b5bd9.json
https://swarm.hiveeyes.org/api/hiveeyes/testdrive/area-42/node-1/item/3b57fcef938b27846d262c83c0f574f8015b5bd9.json?time=2017-07-25T00:40:41Z&has_queen=true
Unter der Haube würde die Datei dann archiviert und (asynchron) analysiert werden.
Retrieval
Eine GET Anfrage an eine dieser URIs liefert dann folgende Antwort:
HTTP/1.1 200 OK
Content-Type: application/json
{
"item": {
"resource": "https://swarm.hiveeyes.org/item/hiveeyes/3b57fcef938b27846d262c83c0f574f8015b5bd9/audio.wav",
"type": "audio",
"name": "beehive_audio_2017-07-25T00:40:41+00:00.wav",
"sha1": "3b57fcef938b27846d262c83c0f574f8015b5bd9"
},
"meta": {
"time": "2017-07-25T00:40:41+00:00",
"has_queen": true
},
"address": {
"network": "testdrive",
"location": "area-42",
"node": "node-1"
},
"analysis": {
"image": {
"sonagram": "https://swarm.hiveeyes.org/item/hiveeyes/3b57fcef938b27846d262c83c0f574f8015b5bd9/sonagram.png",
"power-spectrum": "https://swarm.hiveeyes.org/item/hiveeyes/3b57fcef938b27846d262c83c0f574f8015b5bd9/power-spectrum.png"
},
"report": {
"power-spectrum": "https://swarm.hiveeyes.org/item/hiveeyes/3b57fcef938b27846d262c83c0f574f8015b5bd9/power-spectrum.txt",
"osbh-ml": "https://swarm.hiveeyes.org/item/hiveeyes/3b57fcef938b27846d262c83c0f574f8015b5bd9/osbh-ml.txt"
},
"state": {
"osbh-ml": "active"
}
}
}
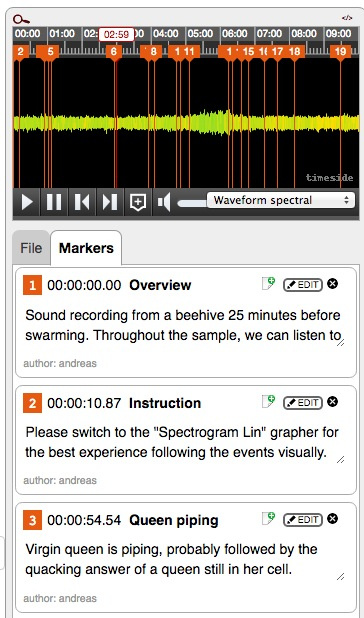
User interface
Eine Benutzerschnittstelle in HTML ist - wie immer - ein etwas höherer Aufwand. Sie könnte aber irgendwann über eine URI à la
https://swarm.hiveeyes.org/item/hiveeyes/3b57fcef938b27846d262c83c0f574f8015b5bd9.html
zur Verfügung gestellt werden und damit die Möglichkeit bieten, Audiosamples komfortabel über eine Webseite hochladen und die Analyseergebnisse schöner darstellen zu können.