Introduction
As already mentioned:
Along the minimalist (in terms of CPU/Energy) approach told by the upper link a very tempting opportunity brought in game via the OSBH section in Aker Forum. The people around Open Source Beehives (OSBH) were directing towards audio from the very beginning and therefore presenting coefficients which where won via machine learning, learned via the audio-samples they had so far. The driving force behind the audio signal processing at OSBH is Javier Andrés Calvo, so we want to send a big thank you to him - we are really standing on the shoulders of giants. Keep up the good work!
The promising output is simply the activity of a bee colony (!). So far it can tell, if they are dormant, active, pre-, post- or swarming, if the queen is missing or hatching. The insights and history of this audio processing can be followed up in the current work status thread in the OSBH Forum. As a foretaste, you might want to have a look at an example diagram from there:
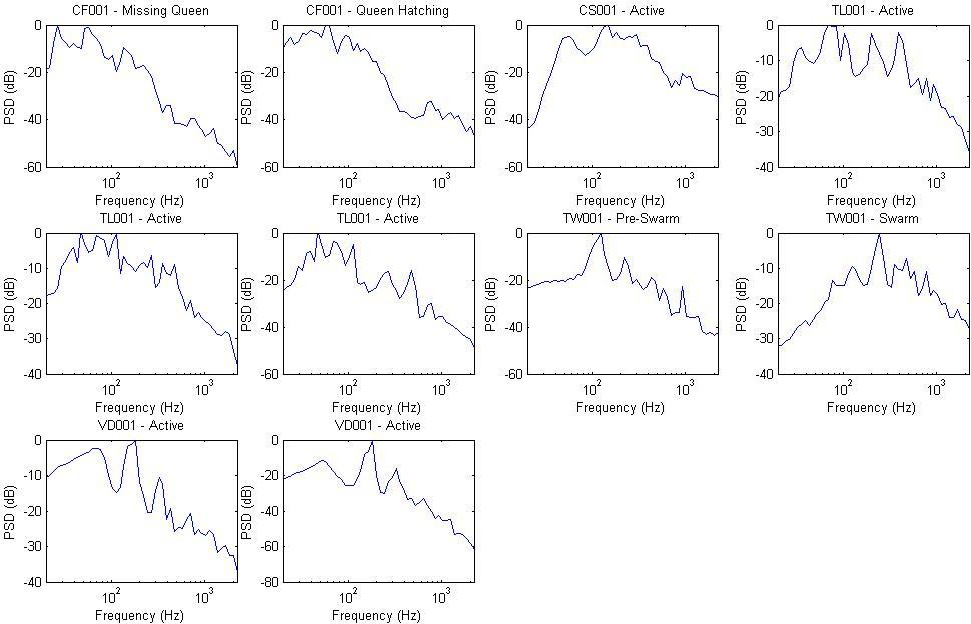
The subject of this thread focuses on the practical use of the knowledge and technic of such. Together with @Andreas - and again the laurels goes to him - we digged into the first very nebulous machine learning code and tried to get something out of it. While the documentation about the method of analysing bee colonies audio outcome is nice to read, there was nothing of such in the repository. We had to play around quite a bit, to understand what kind of audio format processed in another kind of manner the code from the machine leaning repo needs to be fed with to get sane or any output. I don’t want to bore with that and go ahead by telling about the outcome and possible setup that came out of another night shift.
@Andreas wrote a little wrapper script in python, which depends on swiss army knife audio toolkit sox and the python libraries numpy and scipy and of course the mentioned “machine learning” repository, which by the way does not seem to be the code for training, but for analyzing.
Analysis
We were able to feed this program with 50 minutes records of a swarming bee colony found on youtube recorded by Tim Williams of https://adventuresinapiculture.blogspot.de/.
The results are pretty impressive and I am very thankful towards the Open Source Beehives people.
Depending on the time range, we got the following output…
pre-swarm: -25 to -15 minutes before the swarm event
$ audiohealth --audiofile samples/swarm_-25_-15.ogg --analyzer tools/osbh-audioanalyzer/bin/test
20s pre-swarm =========
110s active ==========
210s pre-swarm =============
340s active =======
410s pre-swarm =
420s active =
430s pre-swarm ====
470s active ====
510s pre-swarm ==
530s active ==
550s pre-swarm =
560s active =
570s pre-swarm =
580s active ===
610s pre-swarm None
{u'active': 280, u'pre-swarm': 320}
pre-swarm/swarm: minute -15 to -5 before the swarm event
$ audiohealth --audiofile samples/swarm_-15_-5.ogg --analyzer tools/osbh-audioanalyzer/bin/test
10s pre-swarm =
20s active =
30s pre-swarm =======
100s active =
110s pre-swarm ===========
220s active ==
240s pre-swarm ====
280s active =====
330s pre-swarm ===========
440s active ====
480s swarm =
490s active =
500s swarm ======
560s active =
570s swarm None
{u'active': 150, u'pre-swarm': 330, u'swarm': 120}
swarm: minute -5 to +5 around the swarm event
$ audiohealth --audiofile samples/swarm_-5_+5.ogg --analyzer tools/osbh-audioanalyzer/bin/test
20s swarm None
{u'swarm': 600}
Which means no change at all only swarm-Stimmung.
active: minute +15 to +25 after the swarm event
$ audiohealth --audiofile samples/swarm_+15_+25.ogg --analyzer tools/osbh-audioanalyzer/bin/test
20s active =======================================================
570s pre-swarm ===
600s active =
610s pre-swarm None
{u'active': 560, u'pre-swarm': 40}
HowTo
But for now I want to bring you a snapshot about the tooling and how to use it actually.
Prepare software environment
The audiohealth repository contains all source code and documentation to run it on your own machine.
Please have a look at the audiohealth setup documentation.
Get some audio samples
$ mkdir samples && cd samples
$ youtube-dl --yes-playlist -x --audio-format vorbis https://www.youtube.com/playlist\?list\=PL13A84135EDC8A06A
$ cd .. && ln -s samples audiohealth/samples
You might want to rename the files, since they contains unpredictable whitespace.
$ cd audiohealth/samples
$ mv Sound\ Inside\ a\ Swarming\ Bee\ Hive\ \ -25\ to\ -15\ minutes-sE02T8B2LfA.ogg swarm_-25_-15.ogg
$ mv Sound\ Inside\ a\ Swarming\ Bee\ Hive\ \ -15\ to\ -5\ minutes-Mv5aQl42yA8.ogg swarm_-15_-5.ogg
$ mv Sound\ Inside\ a\ Swarming\ Bee\ Hive\ -5\ to\ +5\ minutes-GKTrV9JJo7Y.ogg swarm_-5_+5.ogg
$ mv Sound\ Inside\ a\ Swarming\ Bee\ Hive\ +5\ to\ +15\ minutes-BIZx-8kLrdw.ogg swarm_+5_+15.ogg
$ mv Sound\ Inside\ a\ Swarming\ Bee\ Hive\ +15\ to\ +25\ minutes-ScdBzaoqukQ.ogg swarm_+15_+25.ogg
Analyze the audio samples
$ audiohealth --audiofile samples/swarm_-15_-5.ogg --analyzer tools/osbh-audioanalyzer/bin/test
[...]
{u'active': 150, u'pre-swarm': 330, u'swarm': 120}
Please also have a look at the audiohealth usage documentation.
Performance
We were running the pipeline on a nanopi Neo, which is similar to a RaspberryPi featuring an Allwinner H3 (qaud core) CPU. While only one core can currently be used for audio processing, getting a vital state out of a 10 minute stereo recording in ogg/vorbis format took around 3 minutes.
This gives a decent opportunity to record a sample, get the state, send it to a backend and go on for the next sample. The idea would be to record shorter samples. The classification based on the OSBH machine learning program computes the state for 10 second chunks, so collecting 1 minute of audio and computing the most prominent state from it could be reasonable.
As we could see in the earliest example, there was a swarm indication already 25 minutes before the swarm. I could cycle from work to the bees in this time.
Hardware Setup and Client Program
There is no work done yet on this…
A first setup could will be based on the nanopi Neo, cheap USB audio interface and microphone.
On our wish list for a service of such are the following features:
- collecting, analysing audios amples and report state to backend
- (?) as swarm indicator (from 0 to 2; pre-, post-, swarm)
- draw and keep (for n weeks) spectrograms of events for review
- draw and keep (for n weeks) audio samples of events for review
- with cheap network around:
- send spectrograms to backend
- send audio files to backend and for machine learning to Open Source Beehives community
… to be continued.