Ich stoße gerade noch auf ein anderes Beobachtungsnetzwerk: naturgucker.de wird vom NABU betrieben. Dieses Jahr findet erstmals eine Kooperation mit dem DWD statt. Im Unterschied zu den sonstigen Beobachtungen des DWD, welche dauerhaft von einzeln bestimmten Ehrenamtlichen durchgeführt werden, wird hier jedermensch aufgefordert, Beobachtungen direkt zu melden.
Mit den genauen Gegenständen der Beobachtung sowie der informationstechnischen Bereitstellung der Daten habe ich mich jedoch nicht befasst – dieser Beitrag soll nur als erster Hinweis auf diese Quelle dienen.
naturgucker mit diy-faktor, das finde ich ja toll: da könnte ich also regelmäßig selbst losstapfen in konzentrischen kreisen um meinen bienenstand, meine beobachtungen bei naturgucker.de hochladen und dann - vorausgesetzt, das lässt sich mit radius um einen ort dort rausziehen - genau meine eigenen beobachtungen (plus das was andere im selben radius um meinen standort eingeben) in den graph importieren. wie gesagt, cool fänd ich das: diese kombination von selber beobachten und in die erfassung und darstellung einfließen lassen.
Dürfen wir dazu aufrufen, das “phenodata” Programm in der aktuellsten Version ordentlich durchzutesten und uns Rückmeldungen oder weitere Wünsche zu übermitteln?
cool. ich mach mich wochenende dran ans testen.
das ist erstmal unabhängig von hiveeyes-grafana, richtig?
ah, ich erinnere mich gerade, die einbindung von wetterdaten läuft ja parallel und ist dann vielleicht recht einfach auch auf die phäno-daten zu übertragen. ich freu mich jedenfalls auf beides.
Richtig, wir haben erstmal die Hausaufgaben gemacht, deswegen ist “phenodata” ein komplett standalone Tool geworden. Wir haben natürlich auf der Agenda, die Ereignisse auch ins Grafana einzubinden, aber der Teufel steckt wie immer im Detail und neben der initialen Grafana Lernkurve will das Ganze auch gut durchdacht sein.
Zuerst einmal vielen Dank - wieder einmal - für die tolle Arbeit, @Andreas! Win10 hat ja nun auch einen guten Linux-Support und man kann mit “bash” in der Eingabeaufforderung ganz schön Ubuntu nutzen.
Dort habe ich alles recht einfach schon vor ein paar Tagen installieren können, auch das update von phenodata 0.3.0 auf die letzte lief problemlos.
Werden Die DWD-Daten eigentlich immer live vom DWD-Server gezogen oder sind die irgenwo gecachet? Wie gesagft gibt es die DWD-Daten auch schon geografisch als “Grid-Daten” aufbereitet. Da müssen wir einmal schauen, ob wir und die nächste Station dann selbst suchen oder ob es Vorteile hat die Grid-Daten zu nutzen, da die z.B. schon berücksichtigen, dass zwischen meinem Standort und der nächsten Station ein Höhenzug liegt, der Unterschied könnte aber auch Erbsenzählerei sein. Ich werde mir auf jeden Fall noch die verschiedenen Datenquellen genauer ansehen, die aktuellen vs. “historic” und die Jahresmelder vs. Sofortmelder.
Die Vorhersage müssen wir uns genau anschauen, ich finde es kritisch, wenn wir Daten die aktuell reinkommen als “Prognose” verwenden. Wenn das direkt neben dem eigenen Stand ist mag das klappen, wenn das in Franke ist und ich auf der Schwäbschen Alb, dann nicht. Der Mittelwert der letzten Jahre vom gleichen Standort geht sicher. Wenn die Meldungen aber erst reinkommen muss man checken ob die schon halbwegs vollständig sind. Der DWE gibt dann immer an von wie viel Prozent der Melder Daten schon vorliegen.
Wir (@Andreas und ich) haben uns die Tage einmal bilateral verständigt und überlegt, welche Daten des DWD für einen Imker als Daten für “seine” Standort herangezogen werden können. Es könnte
die räumlich nächstgelegene Meßstation herangezogen werden oder
Im Dokument steht auch, welche Pflanzen dabei berücksichtigt werden, es kann sein, dass es nicht alle sind, die erhoben werden; weiter werden Qualitätsparameter nicht berücksichtigt - was immer das bedeuten möge. Todo für mich wäre
Eine Karte der bestehenden Messstationen erstellen, um zu schauen, wie diese regional verteilt sind. Wenn diese sehr weit auseinander sind 100, 200 km macht die nächste Station als Datenquelle für den eigenen Stand wenig(er) Sinn und die Grid-Daten wären bevorzugt. – Falls die Stationen engmaschig und gleich verteilt sind, könnte man auch auf die nächste Station zugreifen.
Abgleich, ob in dern Grid-Daten z.B. Pflanzen fehlen oder wir die Qualitätsmarker brauchen, die nicht in den Grid-Daten vorhanden sind.
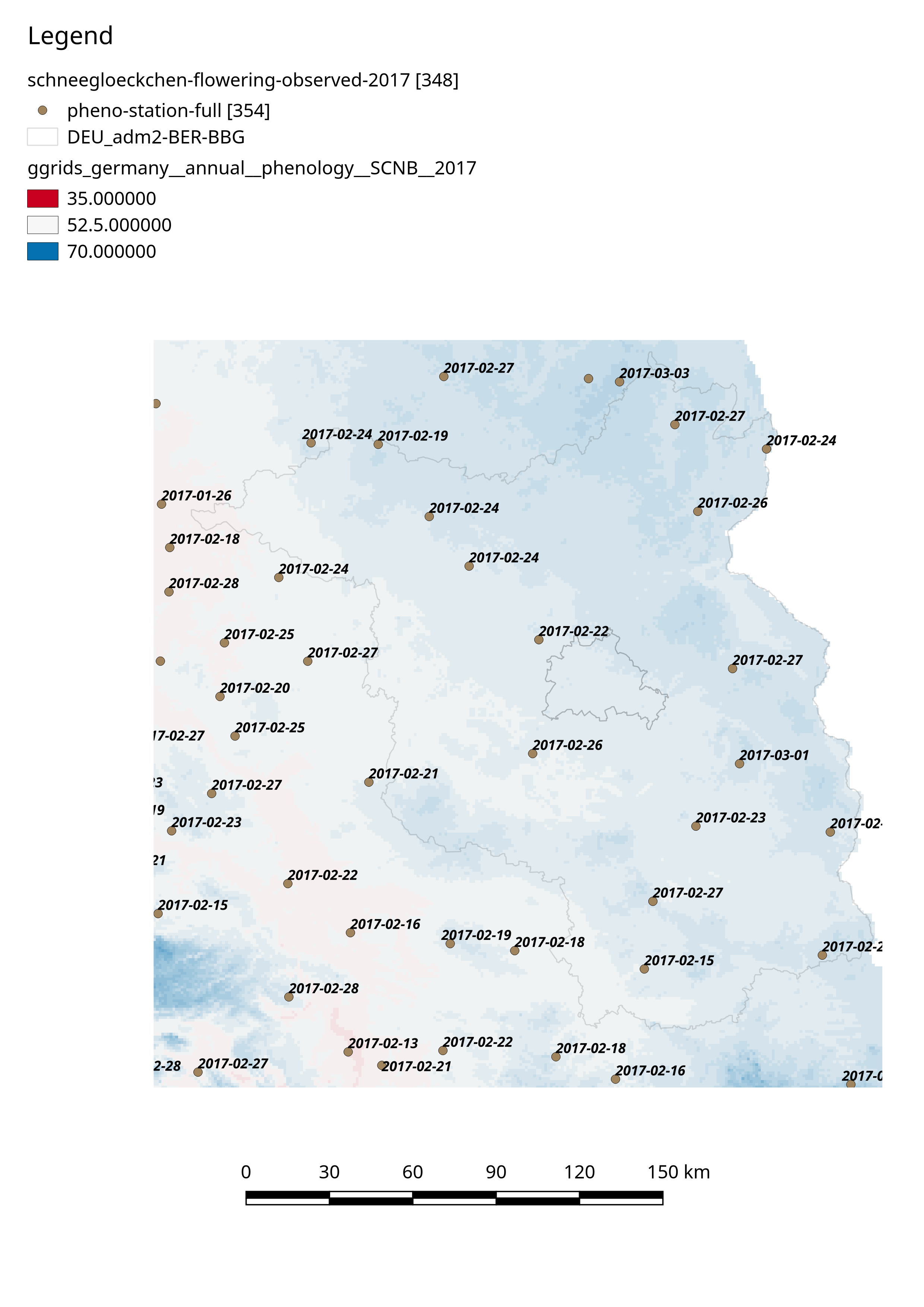
354 davon gab es 2017, Schneeglöckchen-Blüte haben davon 348 gemeldet. In der oberen Karte ist das Ereignisdatum abgetragen, in der unteren der “Jultag”, also das Ereignis als Tag des Jahres (die Legenden der Karten sind überarbeitungswürdig, ich weiß). Der zweifarbige Gradient sind keine Höhenzüge, sondern ist der “Jultag” als gemapter Rasterwert:
Wurden die Karten aus den o.g. Grid-Daten generiert? Wir kamen bisher noch nicht dazu, darauf einen Blick zu werfen, sollten wir sie ebenfalls per “phenodata” erschließen?
Die Grid-Daten [1] sehen ja vogelwild aus, danke ;]. Wenn Du uns auf die Sprünge helfen kannst, wie man die am schlauesten interpretieren kann, sehen wir, was wir tun können. Können wir die Erzeugung der Bilder insgesamt irgendwie automatisieren?
das: phenodata list-stations --source=dwd --dataset=annual --station=berlin funktioniert übrigens nicht (--station=berlin wird nicht honoriert). Und phenodata list-stations --source=dwd --dataset=annual --sort=Stationsname auch nicht (hier ist das Problem --sort=Stationsname)
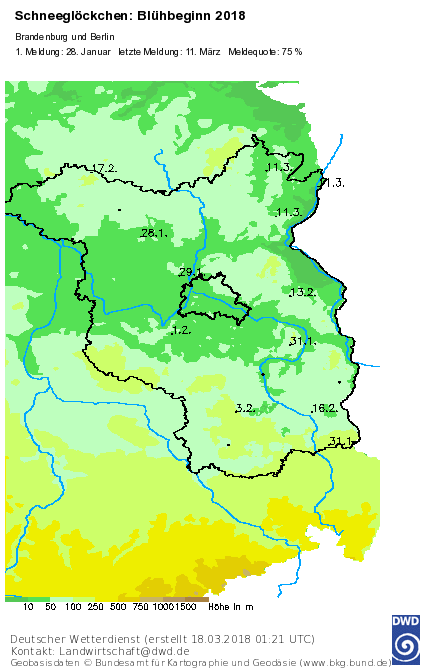
Für dieses Jahr sieht das beim DWD so aus, die bislang letzte Meldung stammt vom 11.März 2018
(Achtung: Farbgradient bedeutet hier Höhenzüge, kein gemapter Blühbeginn wie oben!) - was die Anzahl und Position der Melder angeht, kann ich insofern Deine Beobachtung, @clemens, nicht bestätigen:
Es gibt ca. 1200 Jahresmelder vs. nur ca. 400 Sofortmelder, d.h. wir sollten die Daten der Jahresmelder heranziehen, wenn wir keine aktuellen Daten benötigen.
Hier noch ein Vergleich der Pflanze bei Jahresmelder vs. Sofortmelder vs. Grid-Daten. Bei den Sofortmeldungen tauchen einige Pollenallergene auf, die für die Pollenflugvorhersage recht relevant sind wie Birke und Erle. Warum die Kartoffel bei den Sofortmeldern auftaucht und nicht bei den Jahresmeldern erklärt sich mir nicht.
Die Pflanzenarten der Grid-Daten sind ähnlich reduziert wie die der Sofortmelder.
#proposal Daher würde ich vorschlagen standardmäßig auf die Daten der Jahresmelder zurückzugreifen und die geografischen Grid-Daten für uns zu verwerfen.
Ich habe für die Rohdaten der Tabelle diese querys verwendet: