@Thias Evtl. ist es gar nicht nötig eine eigene Applikation per Device anzulegen.
Laut Webhook Guides kann man die Device ID als Variable für den Pfad verwendet werden.
So könnte man mit einer Webhook, mehrere Devices bedienen und die Device ID im Pfad mit übermitteln.
Beispiel aus dem Webhook Guide:
For example, if the Base URL is https://app.example.com/lorahooks{/appID} and the Path is /up{/devID} an uplink from the device dev1 of application app1 will be posted at https://app.example.com/lorahooks/app1/up/dev1.
Und als ich den Link zum Webhook Guide eingefügt habe, hat mich die Forums-Software drauf hingewiesen, das @MKO hierzu bereits über die Möglichkeit geschrieben hat Variablen für den Pfad bei Webhooks zu verwenden.
Ja, genau darum [1] geht es in unseren Diskussionen, die sich mittlerweile schon etwas in die Länge ziehen. Es muss nun endlich einmal Code folgen, der das optimal realisiert. Bei GH-132 geht die Reise weiter.
Wir peilen auch noch eine weitere Variante an: Mit dieser – “Kanaladressierung via Payload” genannt – wird vollständig darauf verzichtet, die Adressierungsinformationen über die URL zu übermitteln, sondern sie werden stattdessen aus dem Nachrichteninhalt geholt. Dafür darf dieser natürlich noch nicht an der Stelle so stark gefiltert werden, wie Du es derzeit tust [2], sondern muss am besten vollständig übermittelt werden. ↩︎
Daher finde ich auch Dein Beispiel so wunderbar, weil es zeigt, dass es für diese Fälle “mit starker Filterung” gut ist, die herkömmliche Adressierungsvariante zu benutzen, die Kotori schon generisch beherrscht, und nun per GH-81 um den TTN-Dekoder erweitert wurde. ↩︎
Bitte stelle sicher, dass Du für den Produktivbetrieb dann nicht mehr den testdrive Kanal benutzt, sondern Deinen eigenen. Du hast bereits einen Account, ja?
Ja, das geht - auch im Upload Path. Hatte ich im meinem Beispiel oben schon genutzt.
Problem bleibt, dass es auf der gleichen Applikation keine Variabilität in allen Topic Leveln gibt. Ich benötige es zB um Standorte zu unterscheiden. Ebenso testdrive/hiveeyes gehört auf den ersten Topic Level. Und wie gesagt, ich möchte (ihr auch?) alles in einer Applikation.
Auf unseren Anwendungsfall gemünzt, sähen entsprechende URLs damit beispielhaft folgendermaßen aus.
# Device ID kommt aus der URL.
https://swarm.hiveeyes.org/api/hiveeyes/d/testdrive-backyard-hive1/data
# Device ID kommt aus der Nachricht.
https://swarm.hiveeyes.org/api/hiveeyes/data
Das Schema ist nicht viel anders gegenüber den ursprünglichen Vorschlägen. Die Unterschiede sind:
a) Es gibt einen speziellen URL Infix "/d", der einer Device ID vorangeht.
b) Der Realm bleibt außerhalb der Device ID, "hiveeyes" ist also nicht enthalten.
Gedanken
Die hier vorgestellte Lösung ginge auf jeden Fall in diese wartungsarme Richtung, da beide Annahmevarianten parallel implementiert werden und damit von Haus aus zur Verfügung stehen, ohne dass vorab administrativ-operativ eingegriffen werden müsste.
Wenn alles gut geht, würden die TTN-spezifischen Dekodierungsaspekte weiterhin vom bereits etablierten passiven TTN Dekoder abgedeckt, der, wie andere Kotori Dekoder auch, weitgehend heuristisch arbeitet, und daher keine speziellere Konfiguration benötigt. ↩︎
hiveeyes wäre dann in beiden Fällen fixiert und nicht variabel für einem anderem Realm. Könnte also genauso in die Device ID gezogen und aus der URL entfernt werden.? Entsprechend:
# Device ID kommt aus der URL.
https://swarm.hiveeyes.org/api/d/hiveeyes-itest-foo-bar/data
# Device ID kommt aus der Nachricht.
https://swarm.hiveeyes.org/api/data
Ersteres geht voll in die Richtung meiner ursprünglichen Gedanken. Jedoch muss Kotori anschließend erkennen, welche Struktur es im vollen Payload erwartet und das dann entsprechend verarbeiten. Heute nutzen wir ungeschachtelte JSONs und jetzt zusätzlich die stark strukturierten von TTN v3. Was kommt morgen? Ein eigener Endpunkt für jeweilige Varianten und Konventionen will mir immer noch nicht aus der Birne.
Genau. Ja und nein. Der Realm ist fester Bestandteil der Basisadressierung und daher auch fest verdrahtet. Zwar flexibel, aber doch manifest in der Konfiguration pro “Kotori Anwendung”, die das komplette Kanalbündel verwaltet und betreibt. Hier ein Beispiel:
Erst hinter dem Realm geht es dann los, dass der Benutzer individuelle Dinge bestimmen kann, normalerweise startend mit einer Adresskomponente für die Benutzerkennung, bei uns “Imker ID”.
Der Hintergrund dafür, dass wir fest bekannte Präfixe und Suffixe so dringend brauchen – in diesem Fall der Realm, aber auch die bekannten “/data” oder “/event” Suffixe – ist, das wir beide als Ankerpunkte im Suchausdruck brauchen, damit das dazwischen befindliche {address:.*} so flexibel bleibt, verschiedene Strategien bei der Umsetzung der Topologie anwenden zu können.
Das ist jetzt zwar sehr technisch, aber so sieht derzeit die Konfiguration der Vermittlungsschicht von Kotori aus, und irgendwie müssen die neuen Anforderungen durch dieses Nadelöhr.
Langer Rede kurzer Sinn: Der Realm ist nach aktuellen Richtlinien fix in der URL. Ich hoffe das ist nicht allzu enttäuschend für Dich.
Klappt bislang auf unserem Nachbarhost eltiempo hervorragend . Bis es umfällt, können wir ruhig so weitermachen ;]. Nen Geschwindigkeitswettbewerb lässt sich so vielleicht nicht gewinnen, aber in der Haltungs- und Harmonienote wirds ne 10 – im Wortsinn!
Ahja. Genau, nein. testdrive ist ein offener Kanal anstelle der geschützten Benutzerkanäle, und kommt topologisch hinter / untergeordnet zum Realm hiveeyes.
Ich finde das deckt sich doch dann konzeptionell hervorragend mit der Idee, dass es eine “echte” 1:1 Verbindung zwischen einer TTN Anwendung und einer Kotori Anwendung gibt? Im besten Falle heißen sie auch noch gleich. Gleichzeitig reduziert sich der Anteil an Informationen, der in der Device ID stecken muss.
Ich finde es heuristisch akzeptabel, und die Signatur ist bislang hinreichend einzigartig. Wenn es zu langsam wird, müssen wir sie halt in Rust neu schreiben. Wenn sie unzureichend ist, müssen wir sie halt verfeinern.
"uplink_message" in payload and "decoded_payload" in payload
Das volle TTN Payload sicherlich, aber nicht mehr die gefilterte Variante, wie von @Stefan verwendet.
Vielleicht machen wir zwei verschiedene Signaturerkennungen, weil @Stefan’s Anwendungsfall ja bereits nun wunderbar durch die bereits bestehende Implementierung abgedeckt ist, per Einzelgeräteadressierung.
Man könnte sagen, wenn man die möchte, dann bitte so. Und gleichermaßen könnte man sagen, dass die neuen Varianten bitte gerne eine feinere Heuristik bevorzugen würden. Aber ob sich der Unterscheidungsaufwand lohnt?
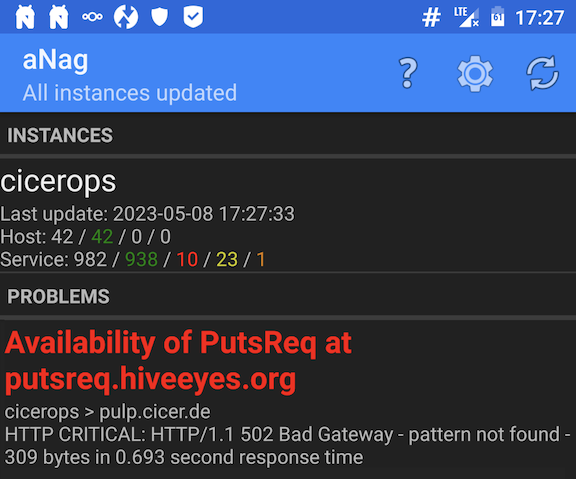
Die Filterung kommt für mich nicht in Frage, denn die spannenden Infos zur Signalqualität stecken nicht in der uplink_message. Worum geht es genau? Siehe die Panels in [1] ganz unten in der ausklappbaren Zeile.
Dass Du Dir das volle Payload nicht entgehen lassen willst, ist klar! Vielleicht ändert @Stefan seine Meinung ja noch, aber einstweilen finde ich es hervorragend, dass damit drei jeweils leicht verschiedenartige Anwendungsfälle hoffentlich endlich gut zusammenkommen werden.
Ich beschäftige mich erst seit kurzem mit TTN und dem Datentransfer zu Hiveeyes. Das sind meine ersten Versuche, da bin ich natürlich sehr froh das die ersten Daten in Grafana ankommen.
Ansonsten bin ich hier aber nicht fixiert und wenn es eine flexiblere Lösung gibt, mit der ich am Ende auch noch zusätzliche nützliche Informationen wie die Signalstärke darstellen könnte, wäre das natürlich von Vorteil und ich würde das selbstverständlich auch nutzen.