Kann sein, dass es nur in der developer-Version geht! Bitte nochmal testen. Gleich auf der ersten Seite (zumindest beim Windows-Toll):
“Include development releases”, ist ein etwas komisches bundling von features und dev vs. non-dev.
Kann sein, dass es nur in der developer-Version geht! Bitte nochmal testen. Gleich auf der ersten Seite (zumindest beim Windows-Toll):
“Include development releases”, ist ein etwas komisches bundling von features und dev vs. non-dev.
Auffällig ist, daß nach dem Zurückstellen an den ersten Standort die RSSI nicht wieder besser geworden ist, sondern etwa 10 dB schlechter bleibt als am Vormittag. Ebenfalls gibt es zwei Spannungseinbrüche in Momenten, an denen die RSSI zweimal spikes nach unten (aka schlechter) hat.
Das sieht mir eher nach WLAN- und ggf. noch Stromversorgungs-issues aus, als nach software-Problemen. Natürlich weiß ich nicht, ob Du in dieser Zeit noch software-Änderungen vorgenommen hast.
Nein, beim FiPy “im Feld” gab es keine Änderungen an der Software, die läuftvom Start an. Das WLAN muss hier durch zwei Kellerwände und ein Fenster, ggf. habe ich die Box auch nicht genau so ausgerichtet wie sie vorher stand.
14 posts were merged into an existing topic: Untersuchung und Verbesserung des Timings bei der Ansteuerung der DS18B20
So mal ein Aktueller Bericht der Langzeittests bei mir.
Immer noch mit Datalogger 0.5.1 auf 1.20.0.rc11
FiPy 0
FiPy 1
WiPy 1
FiPy 2 habe ich selbst vom Test ausgeschlossen, da ich derzeit mit im für das Webinterface arbeiten will. Er hat aber nach 5 Tagen 0 Störungen gehabt.
Abstürze hatte ich bei ihn aktuell aufgrund des abgeschalteten Deep Sleep aber schon ein paar mal.
Die Diskussion rund um die Glitches beim Auslesen der DS18B20 haben wir nun bei Untersuchung und Verbesserung des Timings bei der Ansteuerung der DS18B20 untergebracht.
Herzlichen Dank für die Testberichte! Das hört sich ja vielversprechend an.
Du meinst, das Gerät stürzt manchmal ab, wenn es nicht im Deep Sleep Modus ist? Kannst Du ungefähr eingrenzen, an welcher Stelle oder unter welchen Umständen?
Muß ich noch genauer untersuchen. Habe leider immer den PC nicht an gehabt, um das Logging zu sehen auch ist die Telemetrie aktuell ausgeschaltet, wodurch ich keinen Zeitpunkt ausmachen kann.
Kann aber auch an dem Branch liegen ist aktuell das merge Branch von Diren mit Webserver drauf.
Wie gesagt, muß ich daher nochmal untersuchen.
Vielen Dank für diese Details zu Deinen Beobachtungen. Wir haben die notwendigen Schritte zur Analyse und Lösung bei [Backlog] Terkin-Datenlogger für BOB aufgenommen.
Vielleicht ist das genau das Ding, das @pinguin beobachtet hatte und ich neulich ebenfalls. Ich glaube, dass das Gerät bei mir ebenfalls nicht im Deep Sleep Modus war. Wir sollten hierzu dringend den Watchdog ins Spiel bringen.
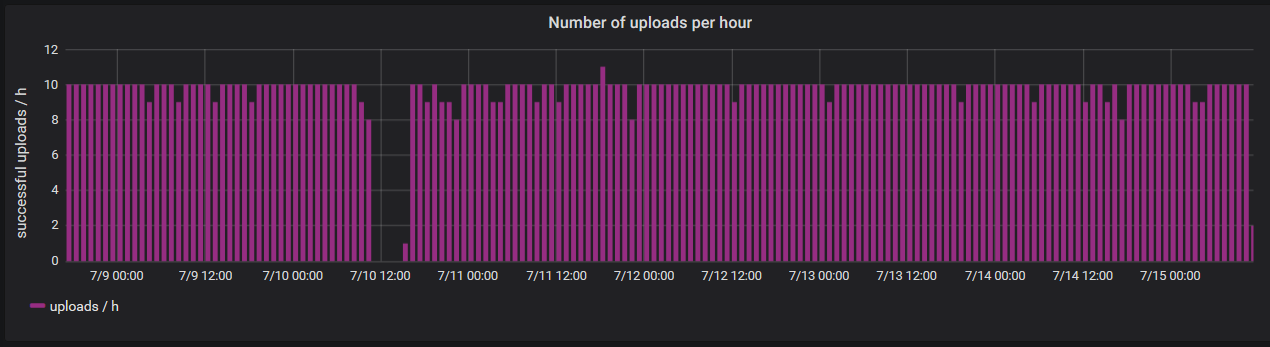
Bisher schaut das – was die Stabilität angeht – alles recht gut aus:
Wir haben fast immer die 9-10 Übertragungen pro Stunde, der längere Ausfall am 2019-07-10 geht auf mein Konto, da habe ich den Node in die Sonne gestellt und damit zu weit vom WLAN weg, es konnten also keine Daten übertragen werden, dass der node aber weiterlief und läuft zeigt die system.time, die auch in der Zeit ohne Datenübertragung zunahm, es gab also keinen Ausfall der Hardware oder reset in der Zeit:
Das Gerät läuft also stabil seit ca. 7 Tagen!
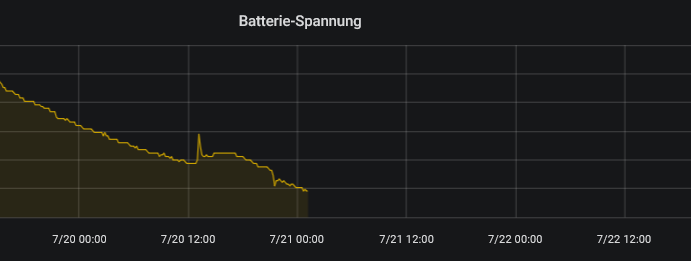
Leider stieg mein Testsystem am 2019-07-20, 23:16 (GMT) komplett aus und wollte auch bis jetzt keine Daten mehr senden:
Beim Blick auf andere Daten ist mir aufgefallen, dass zur gleichen Zeit Stockgewichte um 1 kg – mitten in der Nacht – zugenommen haben und ich erinnerte mich an die Wetterwarnung des DWD! Auch wir hatten hier Wind und Regen.
Bei einer weiteren Inspektion habe ich die Spannung des LiPos gemessen: 3,1 V! Wie passt das zum letzten Datensatz mit 4 V? Ein Blick unter den Blumentopf:
Hmm, der BME lag da “schön” flach ganz unten! Könnte ein ordinärer Kurzschluss über den BME durch viel Regenwasser das Problem gewesen sein?
Nach einem Tausch der Batterie sendet der node wieder und er scheint keine bleibenden Schäden gegeben zu haben.
Habe am Sonntag nacht um 1:20 Uhr das erste mal einen Totalcrash das erstaunliche ist, das absolut zeitgleich beide FiPy abgeschmiert sind. Kann also nur am WLan oder an der Spannungsversorgung gelegen haben. Die Spannungsversorgung ist zusammen über einen 12V mppt Laderegler mit USB Anschluß und 12V Akkus geregelt, da der Akku heute Mittag zu 100% gefüllt war und der eine FiPY durch ab und anstecken des USB neu gestartet werden konnte, schließe ich sie fast aus (der zweite bleibt stumm also auch kein IP Crash und der USB liefert Spannung) .
Den 2. habe ich extra noch nicht neu gestartet, da ich morgen Vormittag mal versuchen will bei ihn ins REPL. zu kommen. Bezweifel zwar das das klappt, aber einen versuch ist es Wert.
Wenn ja, wie sollte ich vorgehen, um möglichst viel Infos über den Ausfall zu bekommen?
Wollte erstmal mit Atom ran, da er beim Anschließend einfach ins Logging verbindet, ohne einen Reset auszuführen.
Interessant. Um das für die nächsten Iterationen zu verbessern, müsste die Aufmöbelung des Watchdogs dank @pinguin nun aus dem aktuellen Master heraus einsetzbar sein. Lass den Datenlogger doch gerne ab sofort mal (testweise) damit eine Weile losrennen.
Ich wüsste nicht, wie man da irgendetwas herausfinden könnte. Die Ausgaben auf der UART sind ja schon geschehen und wurden auf keinerlei Terminal geschrieben, wo man sie rauslesen könnte.
Andere benutzen für solche Feldforschungen einfache aber effektive AVR-basierte Datenlogger.
– TurtlesDataloggers all the way down.
Gut werde also einfach nur schauen ob über UART überhaupt noch was raus kommt.
und ob er sich Aufgehängt hat, oder das Programm abgebrochen wurde…
Wenn ich die UPtime meines Routers vergleiche, könnte das ganze mit einer Zwangstrennung oder Netzstörung zusammen hängen.
@Andreas zur Info. die Version ist immer noch die Ursprüngliche 0.5.1 vom Anfang Juli.
Glaube sogar noch ohne Wachdog.
Könntest du da bitte noch die Software-Version dazu schreiben?
Danke an alle Tester*innen! Ich habe zwei Bitten für zukünftige Tests und deren Dokumentation:
Könntet ihr bitte
Im Rahmen der Untersuchungen zu elektromagnetischen Störungen des Wägezellen-Subsystems konnten wir noch die folgenden Beobachtungen zur Laufzeit feststellen.
Mit dem commit Revert "Adjust waiting time after resetting 1-Wire bus" · hiveeyes/hiveeyes-micropython-firmware@11e8eaf · GitHub vor ein paar Tagen waren hoffentlich endlich alle Sensor-Reading-Adjustments ordentlich im Kasten, so dass sich aus meiner Sicht diese Art von Testreihe überhaupt erstmalig lohnt. ↩︎
Ganz schön flashy übrigens, wenn das Teil in der Nacht in einem dunklen Zimmer ohne Lichtabschirmung steht und ungehindert seine Signalisierungen über die weißen Zimmerwände in den Innenhof reflektieren kann. ↩︎
Direkt beim Starten des Geräts am SBC ist der Datenlogger zweimal sporadisch ausgerutscht.
15.7152 [terkin.device ] INFO : Starting networking
15.7978 [terkin.network.wifi ] INFO : WiFi STA: Networking address (MAC): {'ap_mac': '80:7d:3a:c3:42:bd', 'sta_mac': '80:7d:3a:c3:42:bc'}
15.8128 [terkin.network.wifi ] INFO : WiFi STA: Networking address (IP): ('0.0.0.0', '0.0.0.0', '0.0.0.0', '0.0.0.0')
Traceback (most recent call last):
File "main.py", line 72, in <module>
File "main.py", line 67, in main
File "datalogger.py", line 138, in start
File "device.py", line 70, in start_networking
File "device.py", line 61, in start_networking
File "network/core.py", line 35, in start_wifi
File "network/wifi.py", line 52, in start
TimeoutError: Connection to AP Timeout!
26.5656 [terkin.api.http ] INFO : Setting up HTTP API
Unhandled exception in thread started by <bound_method>
Traceback (most recent call last):
File "network/ip.py", line 24, in start_real
OSError: Network card not available
26.9306 [terkin.api.http ] INFO : Starting HTTP server
Traceback (most recent call last):
File "main.py", line 72, in <module>
File "main.py", line 67, in main
File "datalogger.py", line 143, in start
File "device.py", line 211, in start_network_services
File "network/core.py", line 71, in start_httpserver
File "api/http.py", line 70, in start
File "microWebSrv.py", line 221, in Start
OSError: Network card not available
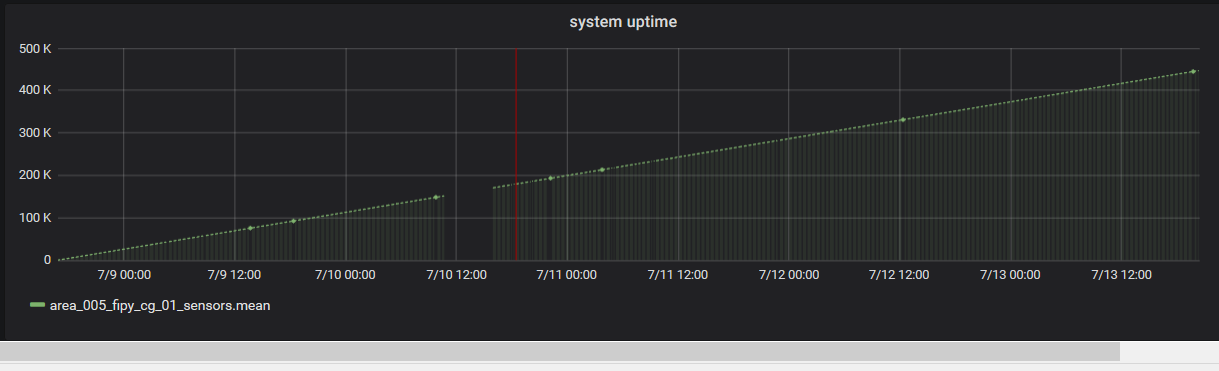
Nach 420.330,4291 Sekunden, also gut 4 Tagen und 20 Stunden, hat der Datenlogger von sich aus neugestartet und ist wohl nach dem Neustart auf dem gleichen Fehler OSError: Network card not available ausgerutscht, der oben schon erwähnt wurde. Hier muss dringend nachgebessert werden.
Als Ursache für das Ausrutschen konnte diesmal dank Monitoring and recording the serial interface output of a microcontroller attached to an UART interface ein CORE DUMP beobachtet werden. Anbei finden sich entsprechende Logs dazu.
24.4832 [terkin.network.wifi ] INFO : WiFi STA: Waiting for network "GartenNetzwerk" to come up, 1 retries left
25.3060 [terkin.network.wifi ] INFO : WiFi STA: Waiting for network "GartenNetzwerk" to come up, 0 retries left
26.1432 [terkin.network.wifi ] ERROR : WiFi STA: Connecting to "GartenNetzwerk" failed
Traceback (most recent call last):
File "network/wifi.py", line 117, in connect_stations
File "network/wifi.py", line 192, in connect_station
WiFiException: WiFi STA: Unable to connect to "GartenNetzwerk"
26.5553 [terkin.api.http ] INFO : Setting up HTTP API
Unhandled exception in thread started by <bound_method>
Traceback (most recent call last):
File "network/ip.py", line 24, in start_real
OSError: Network card not available
26.9223 [terkin.api.http ] INFO : Starting HTTP server
Traceback (most recent call last):
File "main.py", line 72, in <module>
File "main.py", line 67, in main
File "datalogger.py", line 143, in start
File "device.py", line 211, in start_network_services
File "network/core.py", line 71, in start_httpserver
File "api/http.py", line 70, in start
File "microWebSrv.py", line 221, in Start
OSError: Network card not available
Für die Ursache des sporadischen CORE DUMPs könnten “weiche” Fehler sein, die über Single-Event Upsets (SEUs) zustande kommen können [1].
Die exakte Ursache solcher sporadischer Abstürze muss uns an dieser Stelle jedoch gar nicht primär interessieren, wir müssen nur durch optimale Vorbereitung das Chaos gut im Griff haben.
Dankenswerterweise übernimmt der Watchdog-Timer (WDT) an dieser Stelle eine wichtige Aufgabe und führt das Gerät automatisch wieder aus dem Fehlerzustand heraus.
Ein Single Event Upset (SEU) ist ein Soft Error (deutsch „weicher“ Fehler), der beispielsweise beim Durchgang hochenergetischer ionisierender Teilchen durch Halbleiterbauelemente hervorgerufen werden kann. Der Fehler äußert sich beispielsweise als bitflip, also der Änderung des Zustandes eines einzelnen oder mehrerer Bits in Speicherbausteinen oder CPU-Registern, was wiederum zu einer Fehlfunktion des betroffenen Bauteils führen kann. Wissenschaftliches und gleichermaßen Kurioses dazu haben wir auch unter Soft errors caused by single-event upsets (SEUs) zusammengetragen. ↩︎