[Update]
edited at 21:58pm CET
I hope the below formats correctly!
I’ve amended the docker solution as part of my testing.
- I have removed the sox transforms:
- Changed the model sample rate to 8K (same as my recordings)
#command = 'sox "{input}" "{output}" {remix_option} norm -3 sinc 30-3150 rate 6300'.format(input=audiofile, output=tmpfile.name, remix_option=remix_option)
command = 'sox "{input}" "{output}" {remix_option}'.format(input=audiofile, output=tmpfile.name, remix_option=remix_option)
The reason for that is I have been applying the sox transformation prior to passing the wav file through audiohealth. This allows me to rapidly change the behaviour without having to rebuild the docker file while testing.
What am I testing?
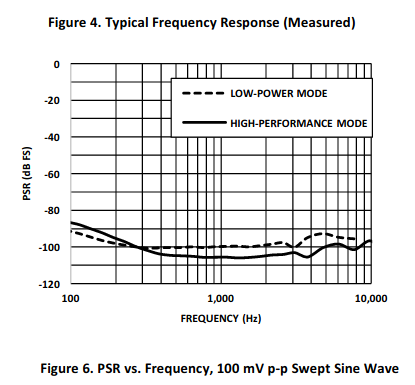
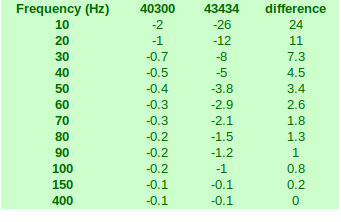
I checked the OSBH microphone used in the buzzbox - it is/was an Invensys ICS-40300 mems
Comparison of Microphones
ICS-40300
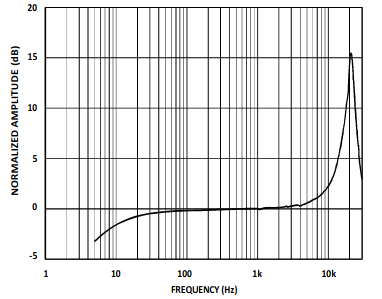
ICS-43434 (my recording hardware)
The ICS-40300 has a very flat response under 100Hz (circa -2Db @ 10Hz) compared to the ICS-43434
- To test if this was a significant factor I took an audio sample (16bits/sample rate=8000)
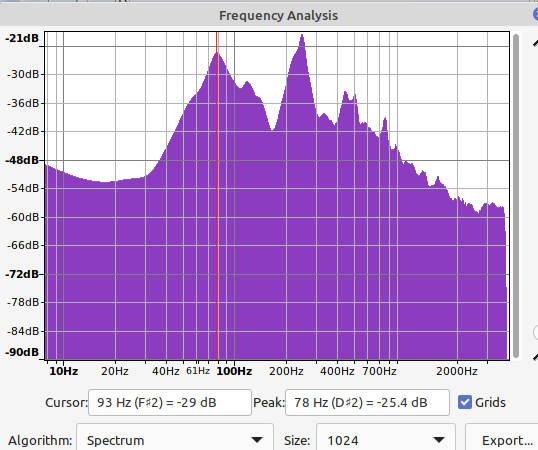
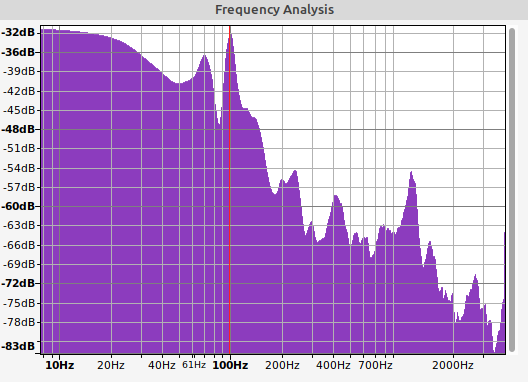
Frequency Analysis:
Note the very flat gain up to 50Hz.
Submitting this to audiohealth (no sox transformations) we get:
Feb 11 17:07:00 0s - 30s active ===
Feb 11 17:07:00 30s - 40s missing_queen =
Feb 11 17:07:00 40s - 70s active ===
This is actually better than the collapsed I was getting before removing the sox transforms (usually collapsed).
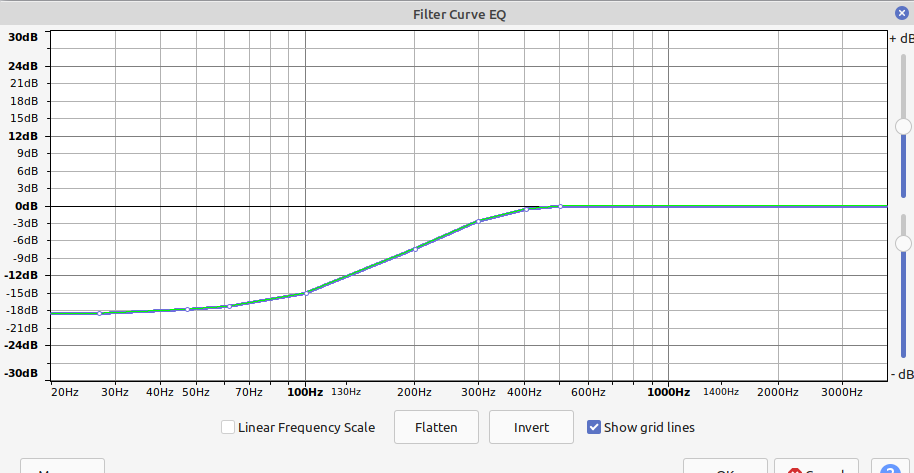
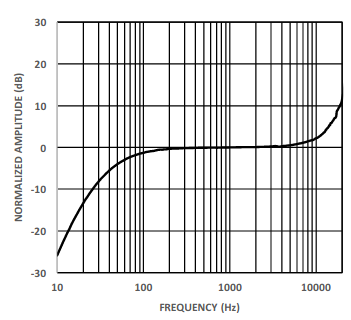
- I then added a filter to Audacity based on the frequency response differences (approximately based on the graphs above) to bias the audio towards the response the ICS-40300 might have produced.
The resulting Audacity Filter Curve:
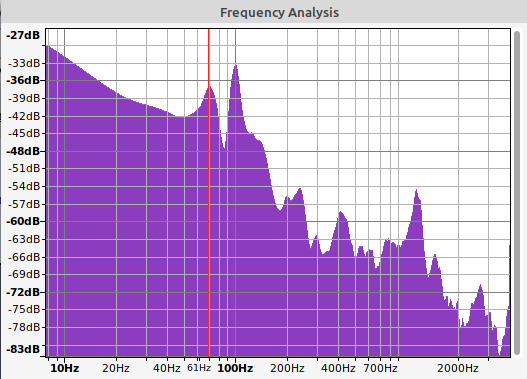
This produces the following:
Note the change in the gain up to 50Hz
Submitting this to Audiohealth we get this output:
Feb 11 17:11:58 0s - 70s active =======
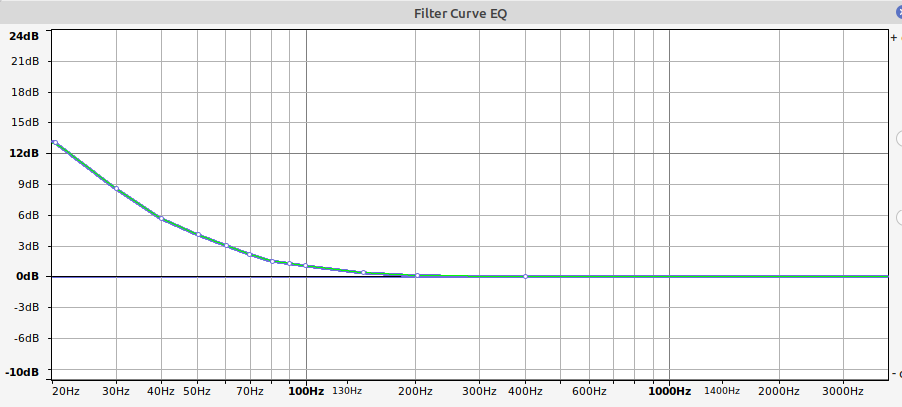
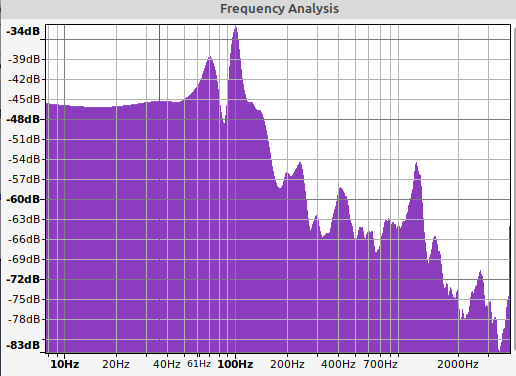
- Sox transform:
To use this in sox I applied the following to the input file (after some trial and error):
sox input.wav output.wav -S bass 24 10 0.4s
(24 Db gain, Centre frequency 10Hz, spread 0.4s)
Producing this:
and this result from
Audiohealth:
Feb 11 18:07:20 0s - 70s active =======
Ideally a FIR filter would be constructed, the sox bass option is far from ideal but easily implemented as quick test.
Given I only have access to the one hive currently the above may just be a one off result and is about as far from conclusive as is possible to be :).
Some questions:
-
Not knowing details, is removing the sox transforms a huge mistake?
-
Changing the sample rate of the OBHS model (in the Docker model it is now 8K). Is this parameter there to be changed - to my thinking if the ML model was using spectrum imaging then that wouldn’t alter in the sub3Khz much ?
-
Do we know the microphones used for the recordings mentioned above? Would be interesting to see if they have any FR bias?
From collapsed to active, a history! (from my home assistant)